




Preface
Fetching online and offline data across different channels to understand your end-users behavior is a primary topic for any enterprise-level brand. Customer 360 view of an end customer gives enormous insight to marketing leaders who can then prepare their strategy to engage and entice these users. A full-stack CDP (Customer Data Platform) helps meet the needs of marketing leaders and analytic folks.
A stable, reliable, and scalable data processing stack is the de facto need for any enterprise CDP solution, and to set up that, data ingestion and extraction architecture need to be solid. StreamSets Data Collector (SDC) has become the preferred tool for many data engineers and data stewards to achieve the ETL and ELT-related needs in this area.
In the traditional approach, the ETL engineers normally have definitive requirements in a place where they know the origin, transformation rules, and destination. Based on the requirements, engineers develop their pipelines and deploy them to production. This has many pitfalls like:
-
You need to have a trained engineer available who can take up the business requirement and implement the pipeline.
-
Transformation and validation rules previously implemented by another engineer for another customer may not be shared with the current team - so the team may spend the same amount of time again to build the functions that are already built previously.
-
Every new development needs to go through the testing cycle and bug fixing.
-
Every new release needs to go through your DevOps process - the effort of rolling out them depends on the robustness and stability of your CI/CD process.
This is certainly a pain area and every data leader should really focus on how they can really address these issues. ETL tools like StreamSets Data Collector (SDC) helps up to a large extent here as they provide a low-code platform using which data engineers can build pipelines quickly. However, a traditional approach to use SDC as-is doesn’t address many issues highlighted above.
In this article, I’m going to share how exactly we have leveraged the SDC REST APIs to automate many of our tasks and saving a lot of time in development, testing, and release management. I hope the large community of data engineers will get some help or ideas from this document.
Prerequisites
The whole intent of this document is to make the data leaders, architects, and managers informed on how differently they should think about addressing these problems. A bit of understanding and exposure to following topics are considered as pre-requisites.
- StreamSets Data Collector (SDC) (We are using 3.21)
- SDC REST APIs
-
Knowledge of Shell Scripts (or any other scripting language)
Problem Statement
We are building a cloud-based multi-tenant platform where any brands whom we get as a customer should be able to build their own connectors. We wanted to give the control of creating connectors into our customer’s hands thereby reducing any human effort involvement from our end.
In addition to data ingestion, we also need to set up a process where customers can create their own connectors to extract the curated data from our platform and send them to their preferred destination.
Solution Approach
Most of the time the end-users of our platform are the marketing leaders. So to have lesser friction, we decided that:
- We will be building a custom UI (simple and intuitive) where users can come and answer few questions to select their source and build the connector.
- Giving the control in the customer’s hand implies that we need to create the SDC pipelines in real-time as and when a customer clicks the buttons on the custom UI provided to them.
-
Every customer will have different requirements for their data. So we need to find a generic way on how we can develop a solution that can meet every customer’s requirements. This means the generic pipelines that we will be building need to be:
-
Schema agnostic
-
Validation rule agnostic
-
Transformation rule agnostic
-
-
We need to build the pipeline only once and test it only once. This means we need to create pipeline templates. Every customer needs to have their own dedicated pipelines which need to be a cloned version of the template we have created.
Based on the above theme - we started our journey 3 months back. I’ll walk you through different project phases which have helped us meet this need. The series of stories below that I’m going to share in a phased manner, is based on:
PART-1: Design/Dev Related Practices
- How have we created a generic pipeline template for getting files from S3 (origin), apply various transformation rules before sending JSON formatted data to Kafka? Kafka is the default destination for our platform to accept data from any external origins.
- How are we getting dynamic runtime requests from end customers via a custom UI to create their specific pipeline?
- How are we configuring the transformation rules that differ from one customer to another customer but the template pipeline still meets the requirements?
- How is the real-time customer-specific pipeline gets created based on the template pipeline?
PART-2 : Versioning, Deployment & On-going Maintenance
- Without using SCH (StreamSets Control Hub), versioning and deployment is not straight forward. While we have an ambition to move to Enterprise version in future, the existing implementation still needs to move forward and hence we had to put up a structure so that we can address some of the core problems around versioning, GIT integration, ease of deployment and post go-live standard operating procedures.
In the current article, I’ll focus on PART-1 while we can keep PART-2 as a future article.
A Custom UI for setting up connectors & journey
We designed a custom UI where customers can come and decide the source connector that they want to build. Below are the steps that a customer will go through while setting up the connector. A simple example presented here where user wants to ingest data to our platform from an AWS S3 bucket.
- Decide your source (S3) and click on “connect”.
-
Enter the basic connection details. As part of this, you will be asked to name your connector along with your S3 credentials, bucket, and file pattern that you would like your connector to process. You can also provide your schedule frequency based on which you want to repeat the file polling.
-
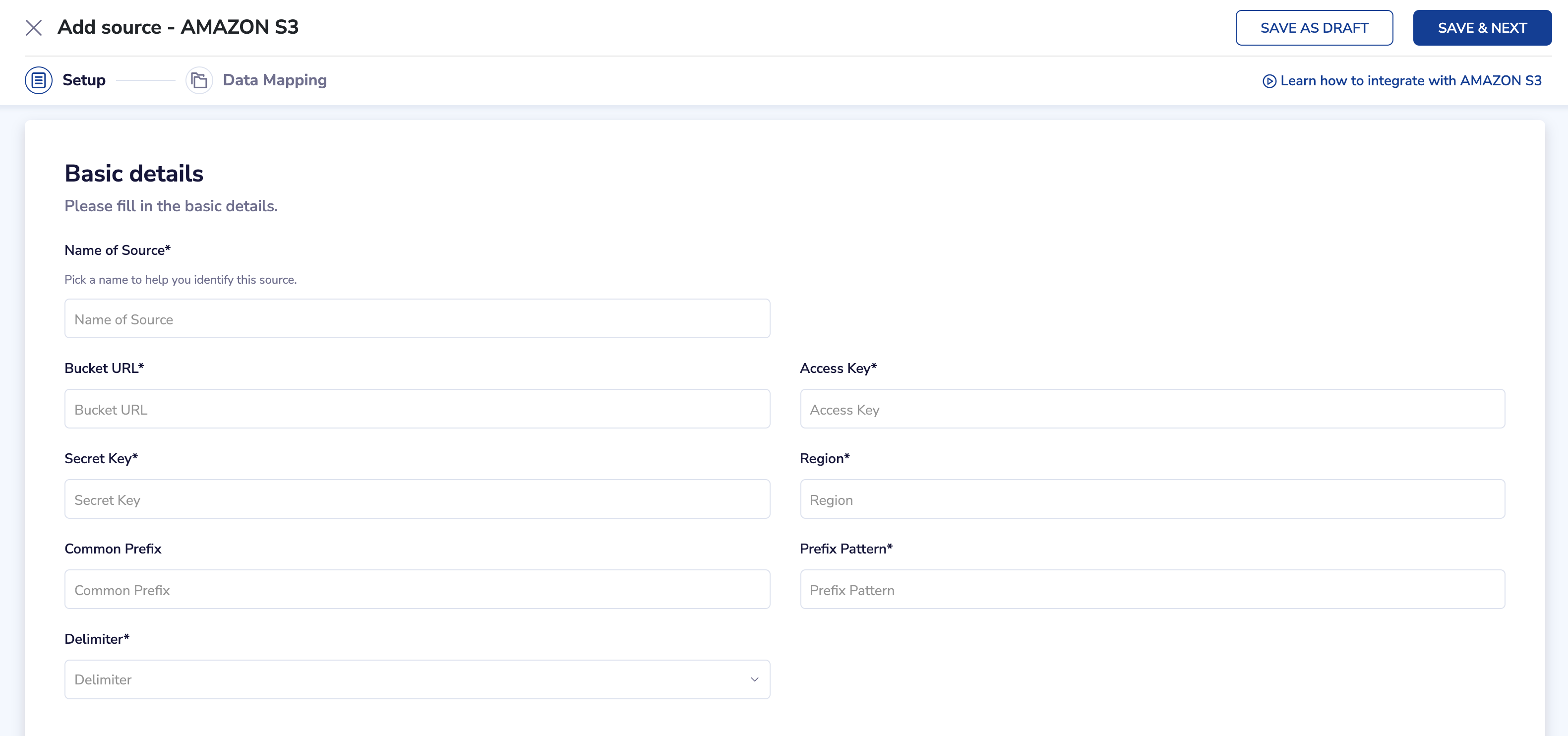
Submitting this request, UI calls backend API request (a validation API), that sends a request to the SDC ETL layer to validate the connection credentials and other entries provided. Hold your thoughts - I’ll provide details on what we are doing in SDC in the later part of this document. Let’s just continue with the flow.
-
The backend SDC pipeline not only validates the connection but also fetches a sample record from the remote origin to discover the data when the connection validation is successful.
-
If the sample record is fetched successfully, we show that to the customer on the next screen for him/her to configure certain mappings and transformations rules.
-
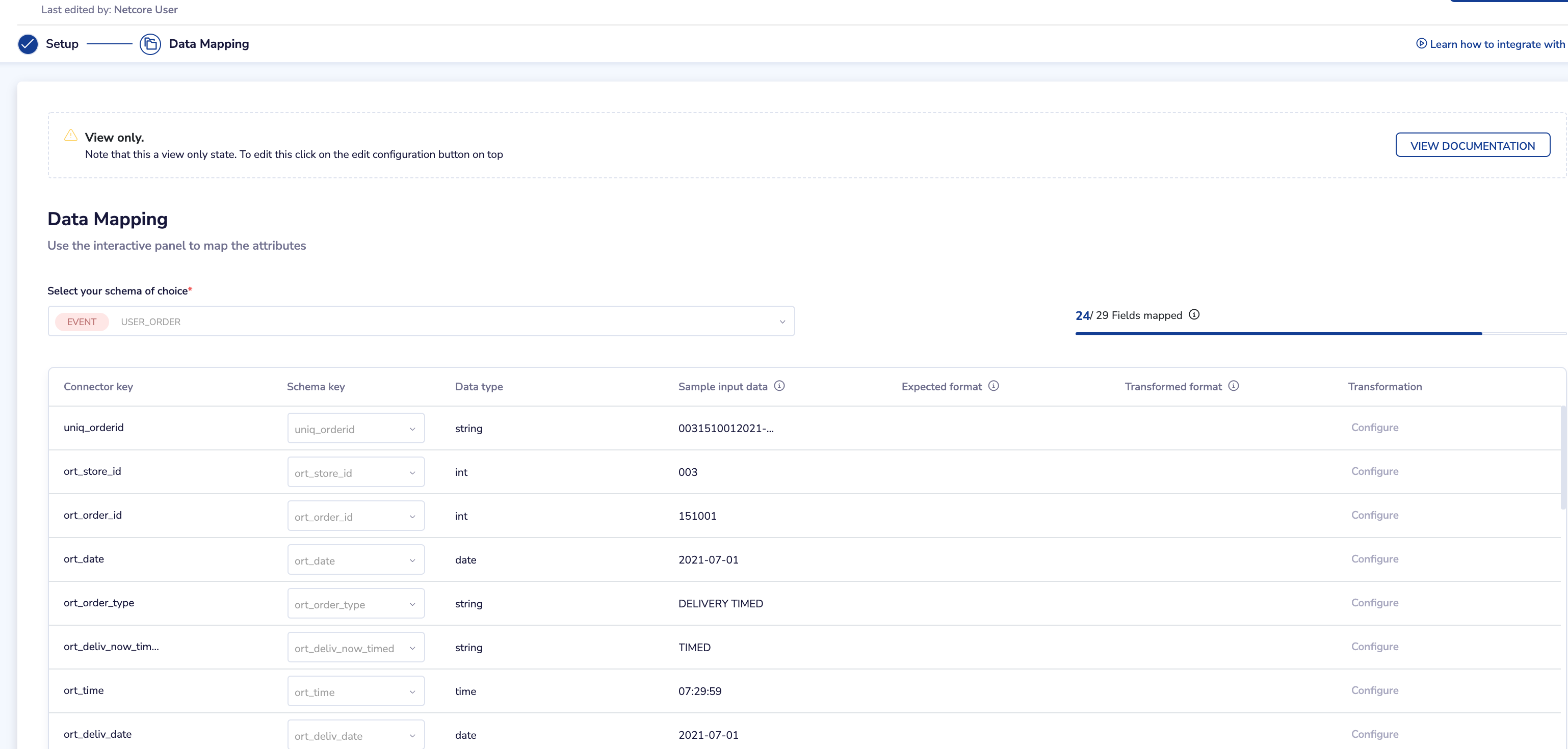
As you can see here, the 1st column with the heading “Connector Key” shows all the column names we have fetched from the sample file in S3 whereas the 4th column with the heading “Sample input data” shows the 1st row fetched from the file. This gives confidence to the customer that we have successfully connected to their origin and fetched a row.
-
On the same screen, we have given the option to customers to configure their connector for other rules like:
-
Rename the column while ingesting data to our platform (2nd Column) - this means how exactly you want to store the data in our platform once it’s ingested. You can leave the 2nd column blank if you don’t want to ingest that column.
-
Apply additional transformation rules for every column if they want to do so while ingesting data to our platform (Last column with Transformation heading). There are various transformation functions that users can select like - str_prefix, str_suffix, str_concat, date/time transformation, mathematical transformation etc
-
-
Finally, the user can press on the “activate” screen to submit a JSON payload to the backend to activate the connector. This is again another “activate” API call to the backend which can take the request and set up a connector based on all choices made so far.
So while the above is the overall journey, there are 2 points where I want to focus more now.
-
Making a “validate” API call to backend - what happens in the backend?
-
Making an “activate” API call to backend - what happens in the backend?
StreamSets Microservice Pipeline
We built a StreamSets Micro-service pipeline to accept the API calls above (validate and activate).
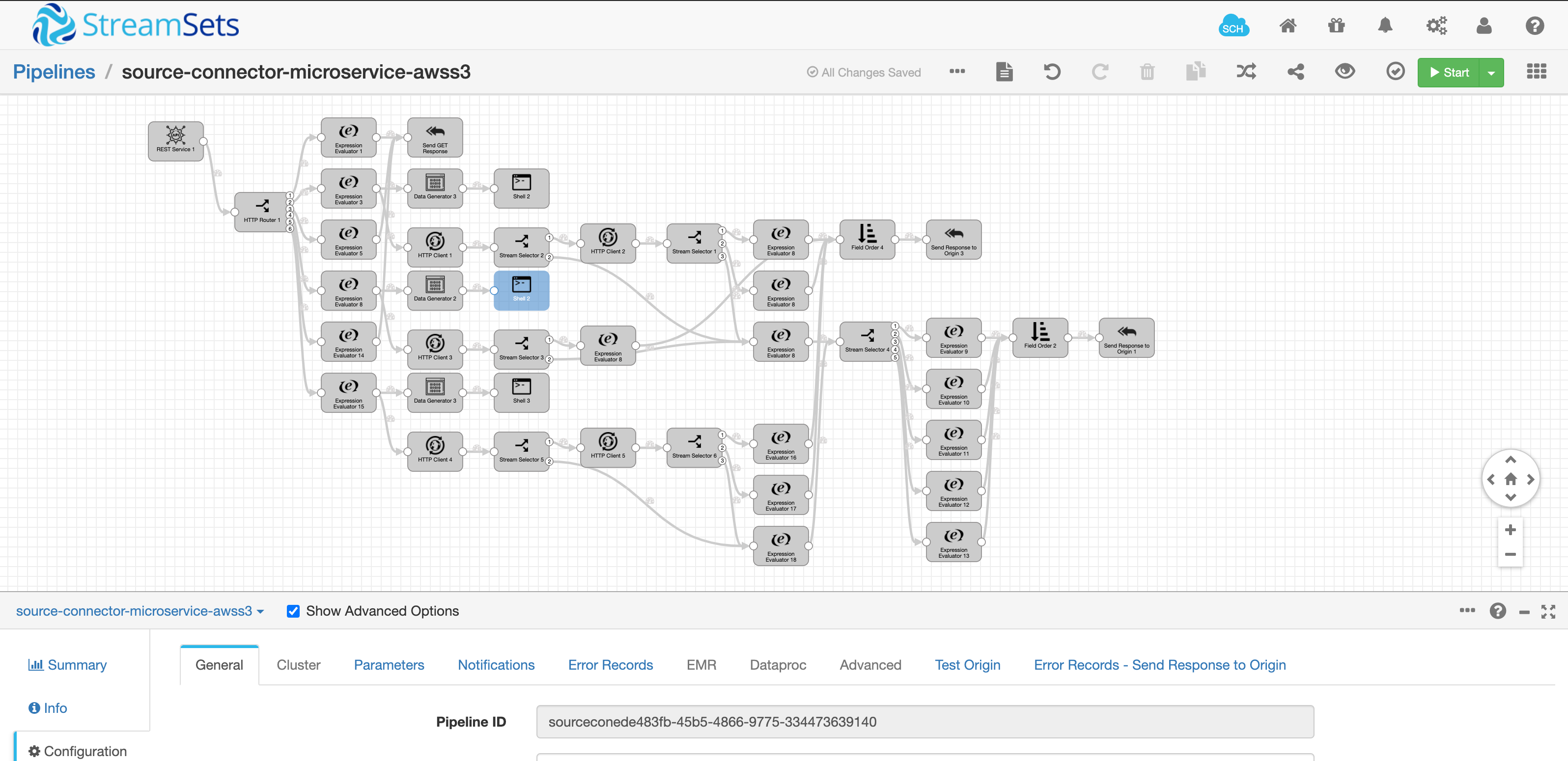
I’ll not get into great details of this micro-service pipeline as that will be a little out of context, but the basic principles of this pipeline are:
- It accepts the REST API calls initiated by UI.
- Based on the action “validate” or “activate” - it selects a path and in both cases, it executes the respective action-based shell scripts deployed in the SDC server.
Series of actions in “validate” API Call
The shell script that is written for “validate” does the following things in sequence:
-
Carries out necessary payload-based validations like checking for mandatory parameters etc.
-
Export the “TEMPLATE” pipeline already designed to extract a single record from a file available in an S3 bucket. Refer to the SDC REST API for the EXPORT pipeline. The result is a pipeline JSON file. Below is a snapshot of a TEMPLATE pipeline that we have created in advance - this is only one time.
-
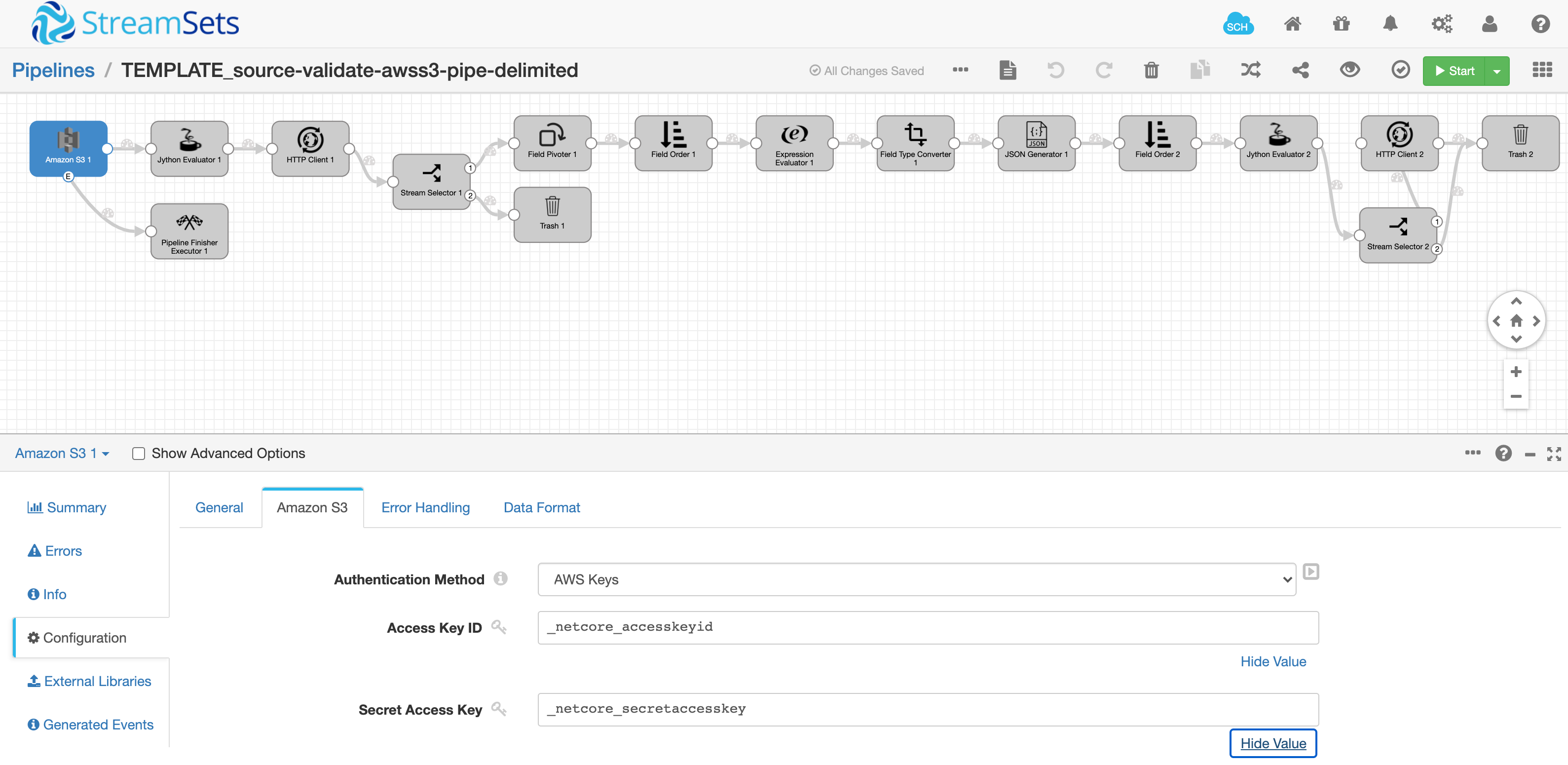
The exported JSON file has all placeholders for the dynamic variables that we have collected in the UI and part of the “validate” REST API micro-service. They are:
-
Access Key ID
-
Secret Access Key
-
Bucket
-
Common Prefix
-
Prefix Pattern
-
-
In the “shell script”, we just string replace the pipeline name and all the above placeholders with the dynamic values coming to us. We have used UNIX “sed” command to achieve the same.
-
Use SDC REST API to IMPORT the above JSON file to the running SDC instance.
-
Use SDC REST API to START the imported pipeline.
-
When the pipeline starts, it starts with all credentials given by the said customer (collected via UI) and on successful connection, it fetches a single record (as we have set Max Batch Size (records)=1) in the S3 origin.
-
We then call an internal API passing on the fetched record to store in DB so that same can be rendered in the front end to the user as part of data discovery.
As you might have realised by this time, we have designed the pipeline as a TEMPLATE only once and any of our customers can now create an instance of it any number of times to validate a connection. Our development and testing efforts are only once and the validation and data discovery is in the hand of the end customer. During the process, we have extensively used the SDC REST APIs. Following is the list of REST APIs used during the “validate” process.
EXPORT the TEMPLATE Pipeline:
#EXPORT THE template_pipeline
http_code=$(curl -o ${TEMP_RESP_JSON} -w "%{http_code}" -X POST -u admin:admin -X GET http://localhost:18630/rest/v1/pipeline/${template_pipeline}/export?rev=0&includePlainTextCredentials=true)
IMPORT the Pipeline JSON File:
# IMPORT THE PIPELINE
http_code=$(curl -o ${TEMP_IMP_RESP_JSON} -w "%{http_code}" -X POST -u admin:admin -v -H 'Content-Type: application/json' -H 'X-Requested-By: My Import Process' -d "@${createSource_log_dir}/${TEMP_RESP_JSON}" http://localhost:18630/rest/v1/pipeline/dummy_id/import?autoGeneratePipelineId=true)
START the imported Pipeline:
# START THE PIPELINE
http_code=$(curl -o ${TEMP_START_RESP_JSON} -w "%{http_code}" -u admin:admin -X POST http://localhost:18630/rest/v1/pipeline/$pipelineId/start -H "X-Requested-By:sdc")
STATUS check of Pipeline:
http_code=$(curl -o ${TEMP_START_RESP_JSON} -w "%{http_code}" -u admin:admin -X GET http://localhost:18630/rest/v1/pipeline/$pipelineId/status -H "X-Requested-By:sdc")
Series of actions in “activate” API Call
The shell script that is written for “activate” does the following things in sequence:
-
Carries out necessary payload-based validations like checking for mandatory parameters etc.
-
Export the “TEMPLATE” pipeline already designed to extract a records from S3 in batches. Refer to the SDC REST API for the EXPORT pipeline. The result is a pipeline JSON file. Below is a snapshot of a TEMPLATE pipeline that we have created in advance - this is only one time. I know it looks very complex - but don’t go by the complexity of the pipeline as the complexities are only for one time to develop and test.
-
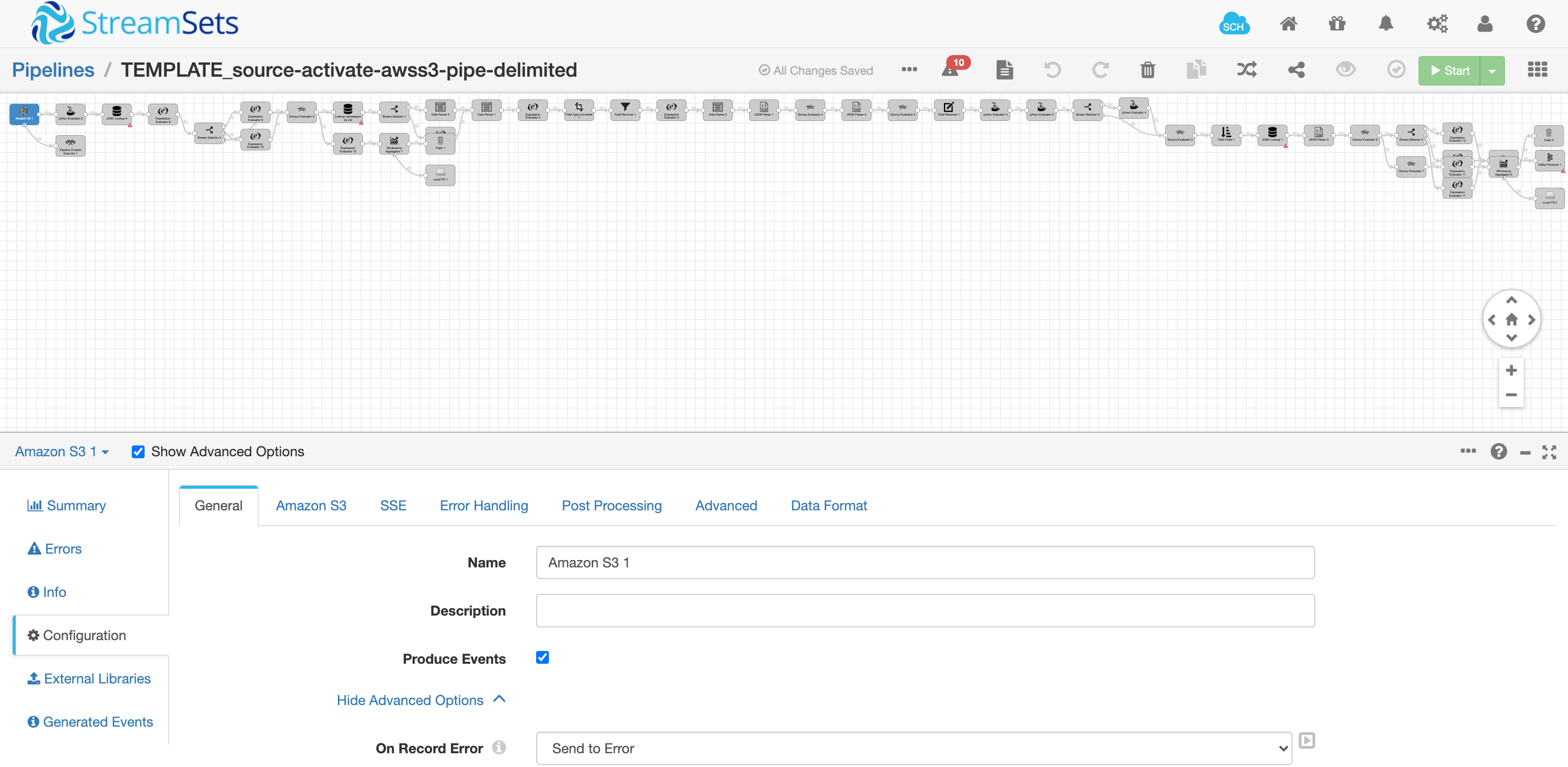
The exported JSON file has all placeholders for the dynamic variables that we have collected in the UI and part of the “validate” REST API micro-service. They are:
-
Access Key ID
-
Secret Access Key
-
Bucket
-
Common Prefix
-
Prefix Pattern
-
-
Apart from that, the pipeline has been designed to have a set of static config parameters that have placeholders that get updated based on the dynamic parameters coming as part of the “activate” API call.
-
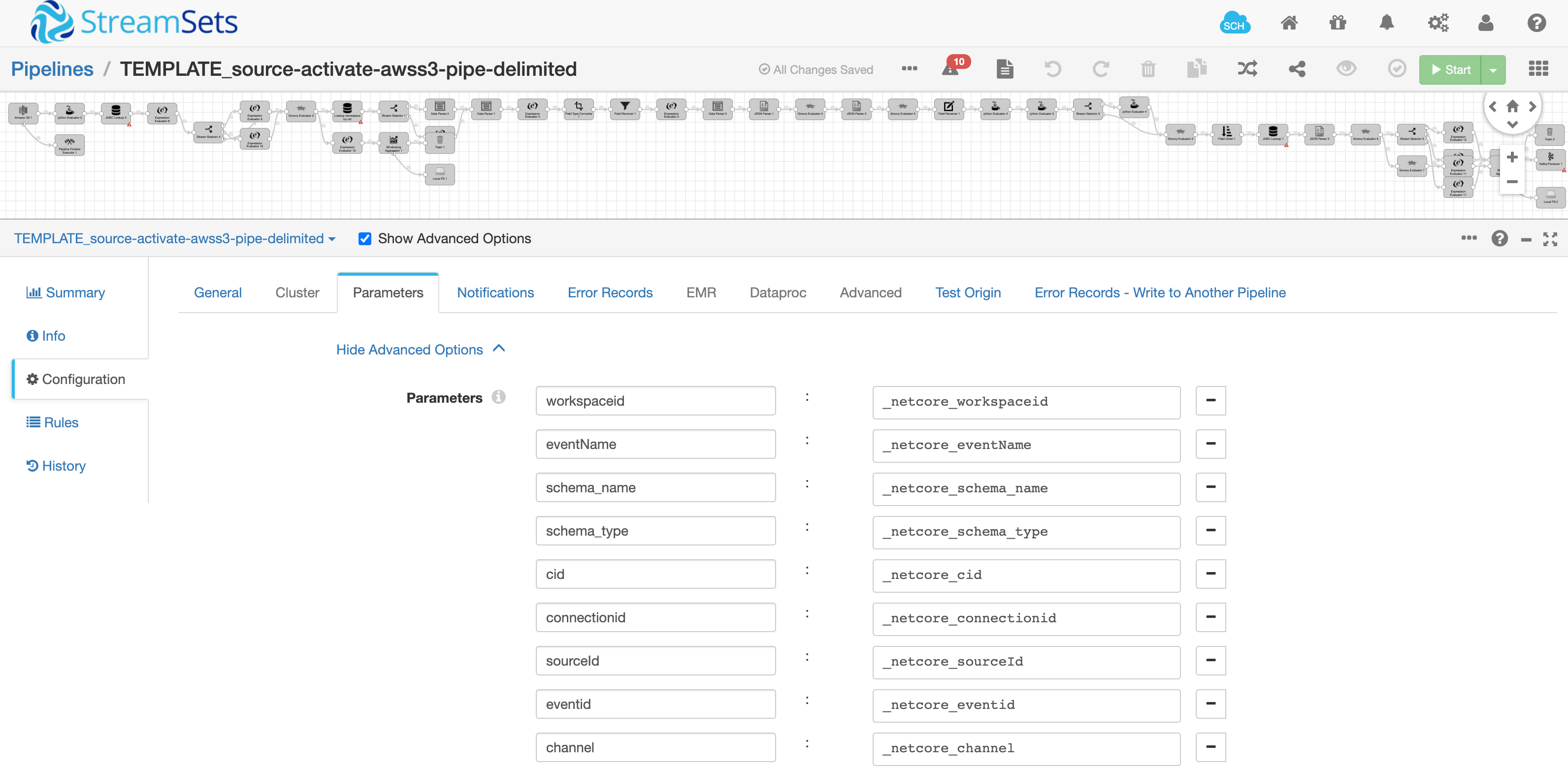
-
In the “shell script”, we just string replace the pipeline name and all the above placeholders with the dynamic values coming to us. We have used UNIX “sed” command to achieve the same. As you can see, we update the connection column mapping rules, data transformation rules, datatype mapping rules as part of UNIX sed command.
-
The pipeline is a little complex as we have utilized multiple-stage processors and Jython evaluators to implement dynamic logic for column renaming, data type change, customer transformation function evaluation, etc. I’m currently not highlighting them here in great detail, but should you have any interest to look at those functions, look out for the StreamSets Community site and search for my micro-blogging. In the coming days, I’ll start sharing them as smaller topics.
-
Use SDC REST API to IMPORT the above JSON file to the running SDC instance.
-
Use SDC REST API to START the imported pipeline.
-
When the pipeline starts, it starts with all credentials given by the said customer (collected via UI).
-
The shell script also sets up a CRON JOB based on the sync frequency selected by the user - the CRON JOB takes the pipeline ID of the imported JSON and utilizes SDC REST API to run it as a scheduled job.
All the SDC REST APIs mentioned in the “validate” section were useful for “activate” as well.
Post Activation Process
As you can see above, we have a generic process laid out where any number of customers can create any number of pipelines where the source is S3 and then want to ingest their record to our platform. We did the design/development/testing/release of only 2 TEMPLATE pipelines (one for validation and data discovery and the other for the final pipeline setup). We have saved a lot of engineering time to develop pipelines for every new customer and every new requirement they have to bring data from S3.
But what about post-activation maintenance? What if the customer wants to check the status of a running pipeline or STOP a running pipeline or START a pipeline before its scheduled time?
SDC REST APIs are very useful in this case as well. Below is a list of APIs that we have used for various actions:
- STOP PIPELINE:
http_code=$(curl -o ${uniqid}.json -w "%{http_code}" -X POST ${userauth} -X POST ${endpointURL}/rest/v1/pipeline/${pipelineId}/stop -H "X-Requested-By:sdc")
- START PIPELINE:
http_code=$(curl -o ${TEMP_START_RESP_JSON} -w "%{http_code}" -u admin:admin -X POST http://localhost:18630/rest/v1/pipeline/$pipelineId/start -H "X-Requested-By:sdc")
Conclusion
In this article, I tried to share the concept that we followed to make our approach scalable and give enough control to our end customers. Giving controls to end customers not only builds their confidence in our platform but also gives great visibility to them of what exactly they are doing. At the same time, we were able to achieve our core motive to save time and energy for our developers who can now avoid doing the repeated development and testing rather than focus more on other core businesses.
As an author, I’m only sharing the methods/processes we have adopted in our design. I’m not at all mandating that things have to be done in this way. I also believe that with the availability of SDC 4.x, the approach we have taken can also be done a little more efficiently. In case any of you have tried to address the problem statement in any different ways, I would love to hear from them as a comment to this blog.
In the next upcoming article I’ll try covering the approach we have taken with SDC for pipeline deployment and on-going maintenance.