I currently have a problem to see in which field i can use:
- Just text
- /record_fields
- Functions:
Portal - StreamSets Docs
Concrete example:
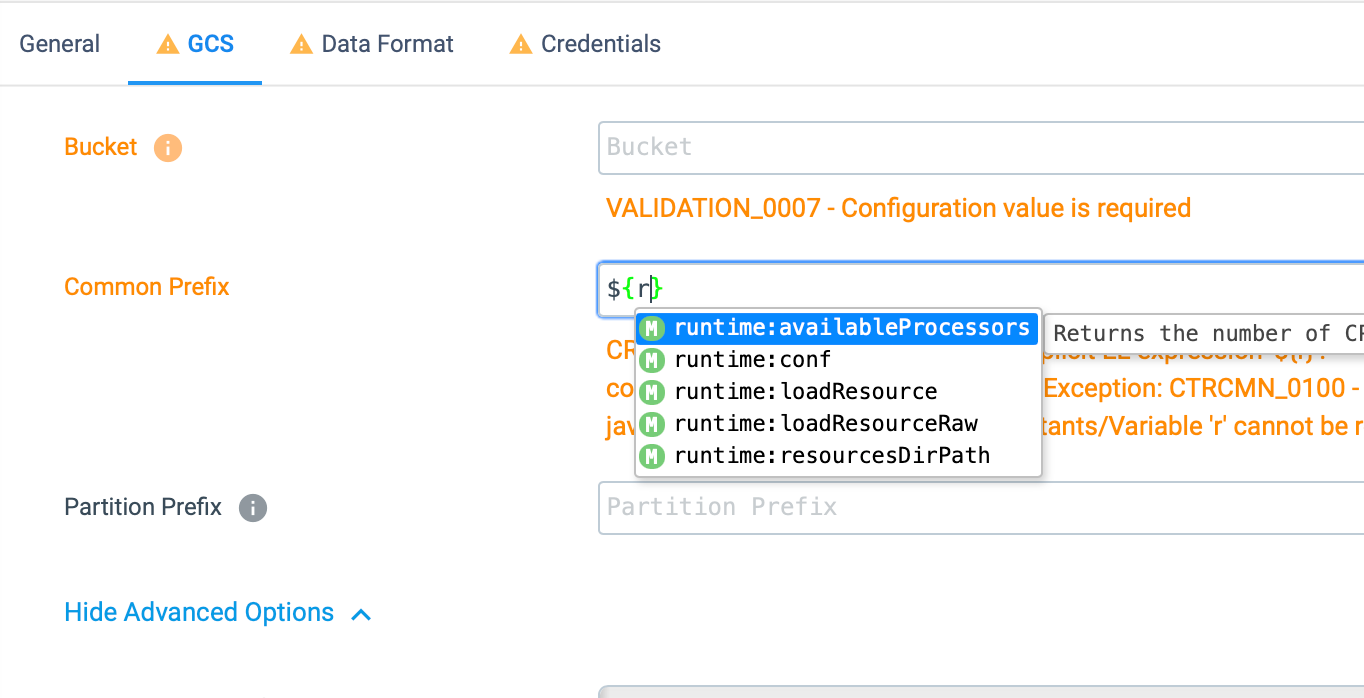
I used Google Cloud Storage Destination which offers and i wanted to make use of some
values from the records in the name of the file i create so like that i wanted to set:
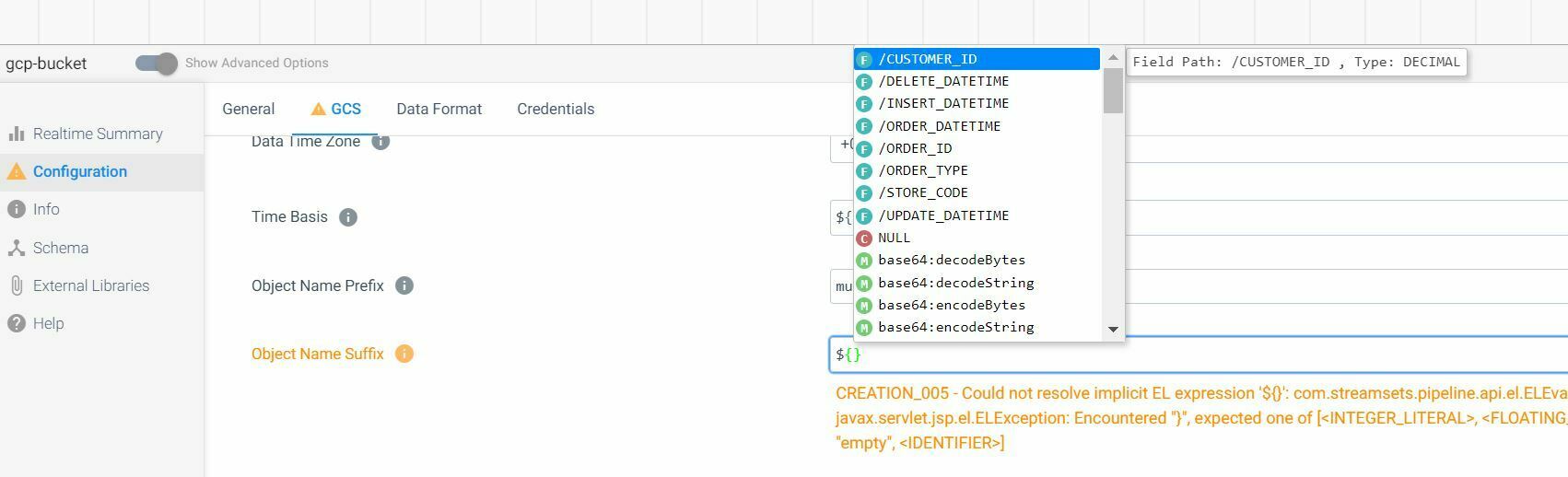
Object Name Prefix or Object Name Suffix to:
sdc-order-${record:value('/ORDER_ID')}-${record:value('/ORDER_TYPE')}
Doing that results in error:
“CREATION_005 - Could not resolve implicit EL expression 'sdc-order-${record:value('/ORDER_ID')}-${record:value('/ORDER_TYPE')}': com.streamsets.pipeline.api.el.ELEvalException: CTRCMN_0100 - Error evaluating expression sdc-order-${record:value('/ORDER_ID')}-${record:value('/ORDER_TYPE')}: javax.servlet.jsp.el.ELException: No function is mapped to the name "record:value"”
i had to find out that this does not work.
I could only use:
- Plain Text
- Pipeline Paramaters ( ${pipeline_parameter})
So how can i see what works in which area as it costs quite some time to figure at what works and what does not work.
Many thanks for your help.
Best answer by Giuseppe Mura
View original