



Hello,
We’re trying to create a transformer pipeline with Origin: AmazonS3 , Destination: Azure ADLS and compute is on Azure Databricks.
We tried to break is down into smaller pieces.
- S3->ADLS pipeline with Streamsets own cluster worked fine.
- Random data source to ADLS with Databricks compute worked fine.
But when we try to bring in all 3 components together, we are getting stage library specific errors which are conflicting. We have tried different combinations from the list in the attached picture.
In this particular scenario, what are the stage libraries we need to choose?
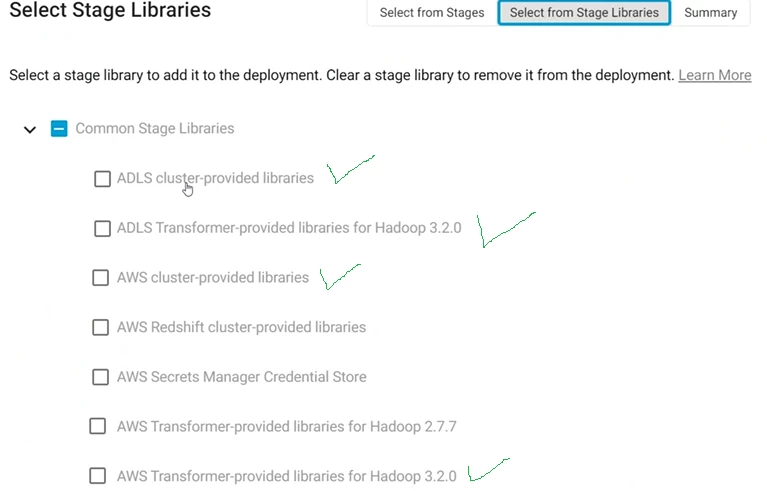
Best answer by Dhanashri_Bhate
View original