



In this article, our focus will be on utilizing the Elasticsearch 7.9.0 library to load data from a Kafka topic into Elasticsearch.
We are going to use following environment:
- Kafka Consumer Origin [Kafka 2.7]
- Elasticsearch Destination [Elasticsearch Library 7.9.0]
Currently, the source Kafka topic "elastic" contains approximately 5327 records. Now, let's delve into the details of our pipeline setup:
- Stage1: Consumer will fetch records from topic with the rate of 1000 records per batch.
- Stage2: We are going to remove the some unnecessary field from each record.
- Stage3: Credit card details will be masked and only last 4 digit will be visible.
- Stage4: Upload the data to Elastic with index customer_data.
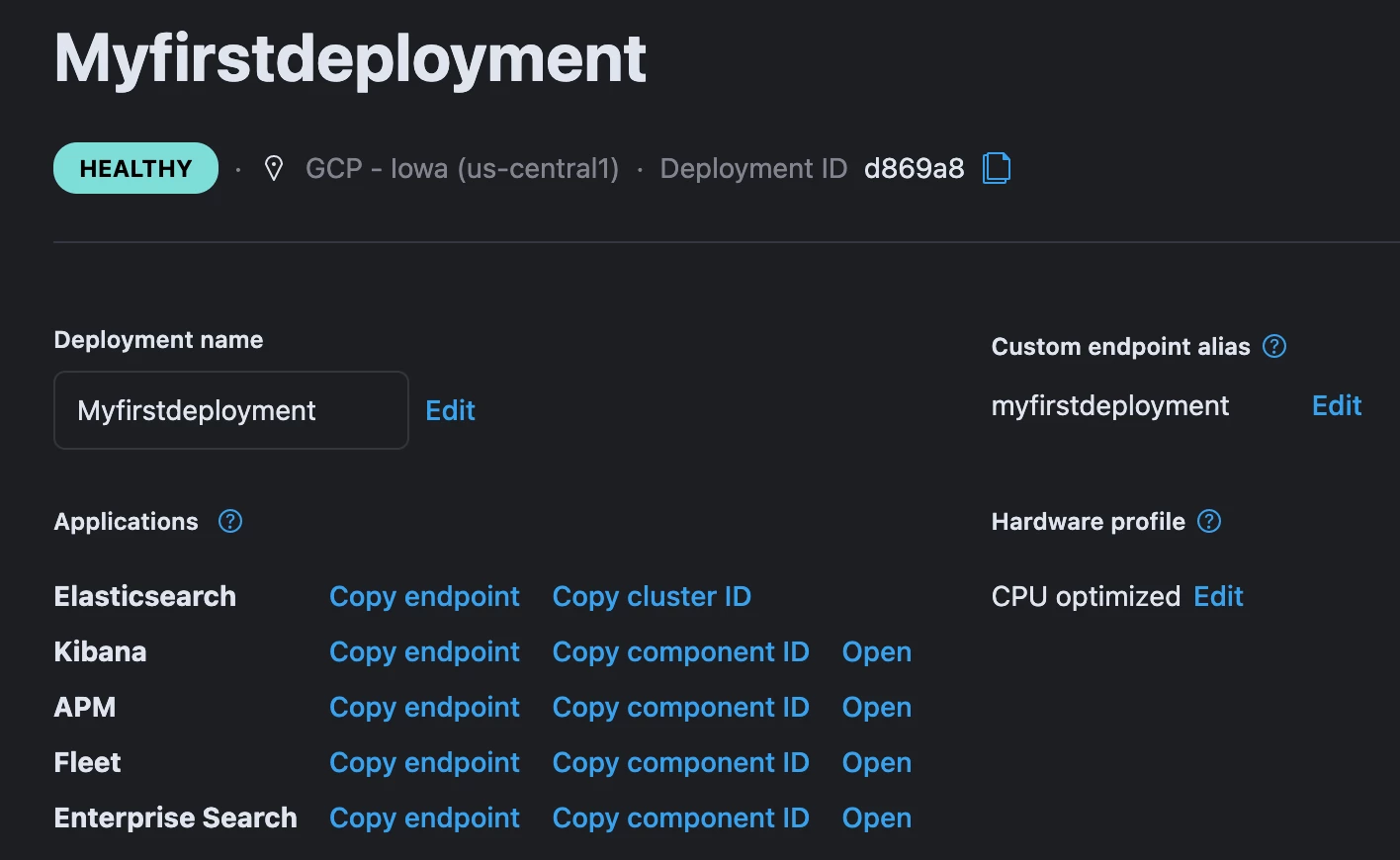
To run this pipeline, We need to setup the Elasticsearch deployment and get the username password + endpoint details from the ElasticSearch » Deployment section.
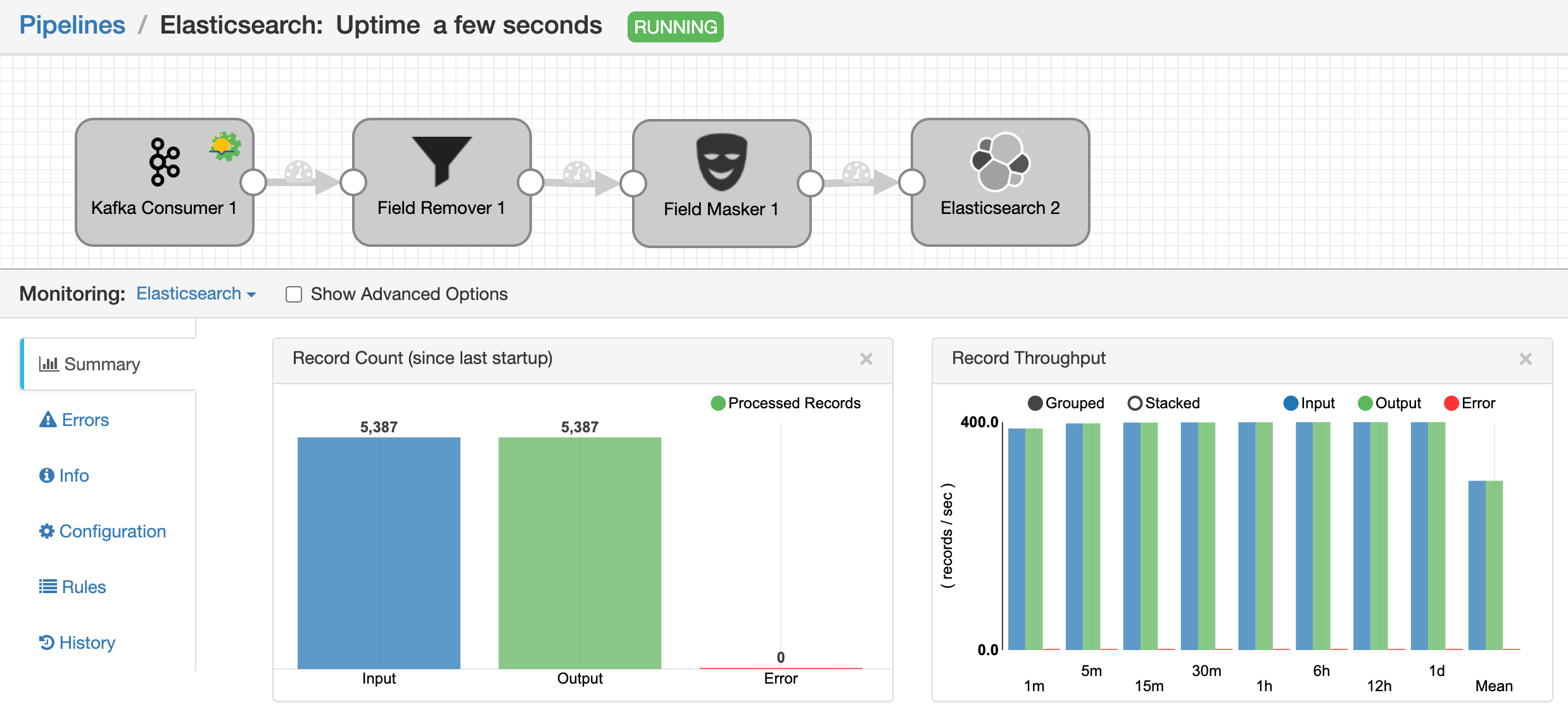
After successfully validating the pipeline, we proceeded to start the pipeline, which in turn successfully processed approximately 5387 records from Kafka to Elasticsearch. Here is the screenshots of pipeline execution:
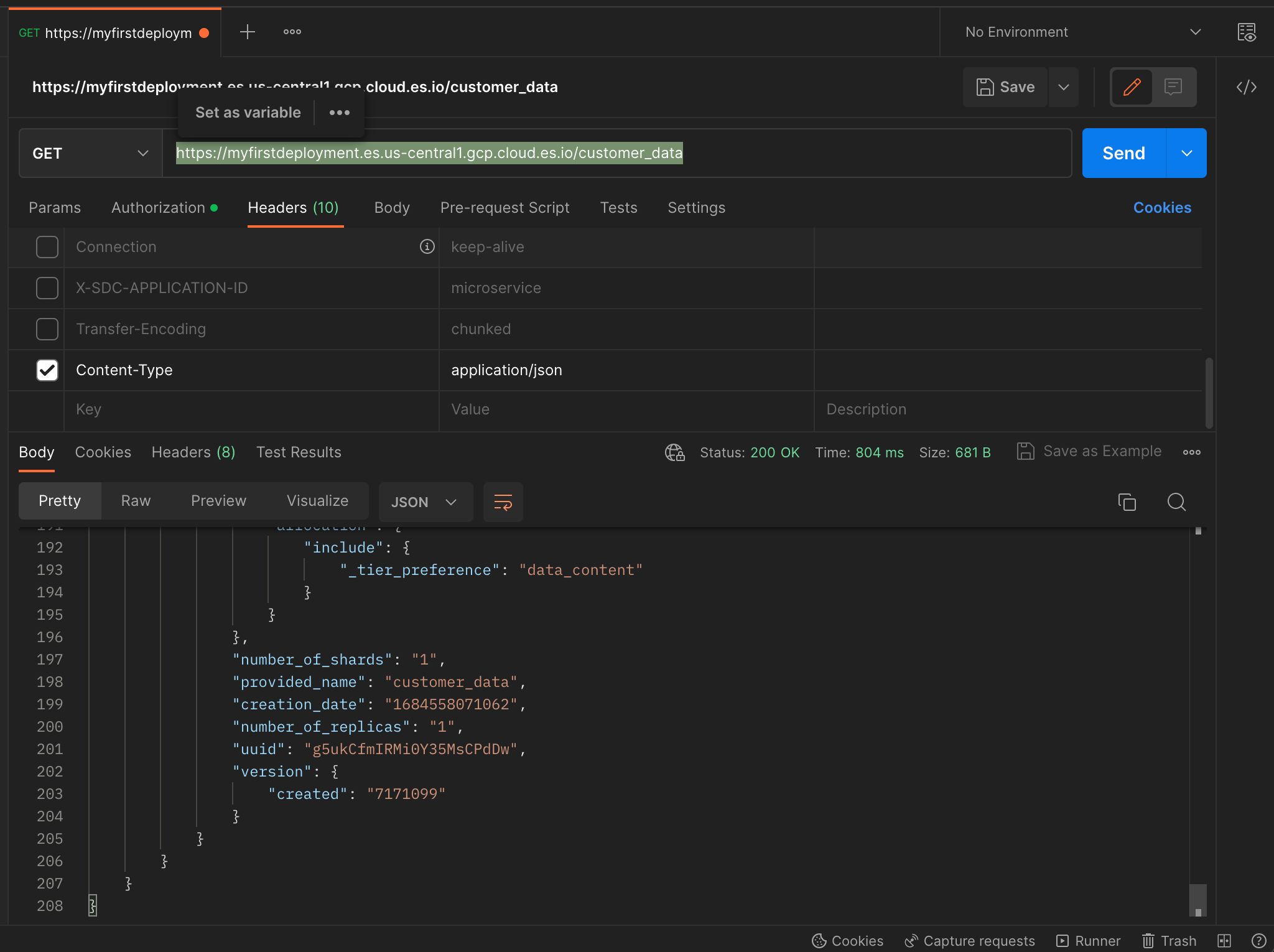
Now that all the data has been ingested into Elasticsearch, we can verify its presence by performing a GET operation using the curl command from the postpan application.
Alternatively, you can also run a curl command directly from your local computer to confirm the data's successful ingestion.
That covers the process of connecting to Elasticsearch from the StreamSets Data Collector.
Before diving into working with Elasticsearch, it's important to familiarize yourself with some key Elasticsearch terminology. Here are a few terms you should know:
Shard: A shard is a subset of a larger index in Elasticsearch. When you index data into Elasticsearch, it automatically divides the index into smaller, manageable pieces called shards. Each shard is a self-contained index that can be stored on a separate node in a cluster. Sharding allows Elasticsearch to distribute and parallelize data across multiple nodes, enabling horizontal scalability and faster search and retrieval times.
Indexing: Indexing in Elasticsearch refers to the process of adding or updating documents in an index. Documents are typically in the JSON format and represent individual data entities. When you index a document, Elasticsearch analyzes its content, extracts the relevant information, and stores it in an optimized data structure called an inverted index.
Document: In Elasticsearch, a document is the basic unit of information and represents a JSON object that contains data. A document can be any structured data, such as a customer record, a log entry, or a product description. Each document is uniquely identified within an index by a document ID, which can be manually specified or automatically generated by Elasticsearch.
[1]. https://www.elastic.co/guide/en/elastic-stack-glossary/current/terms.html#terms
[2]. https://cloud.elastic.co/registration?elektra=en-ess-sign-up-page
[3]. https://github.com/AkshaySJadhav/Elastic_Experiments/tree/61cdced30a99545f590f7efce1b092359c87bca4