

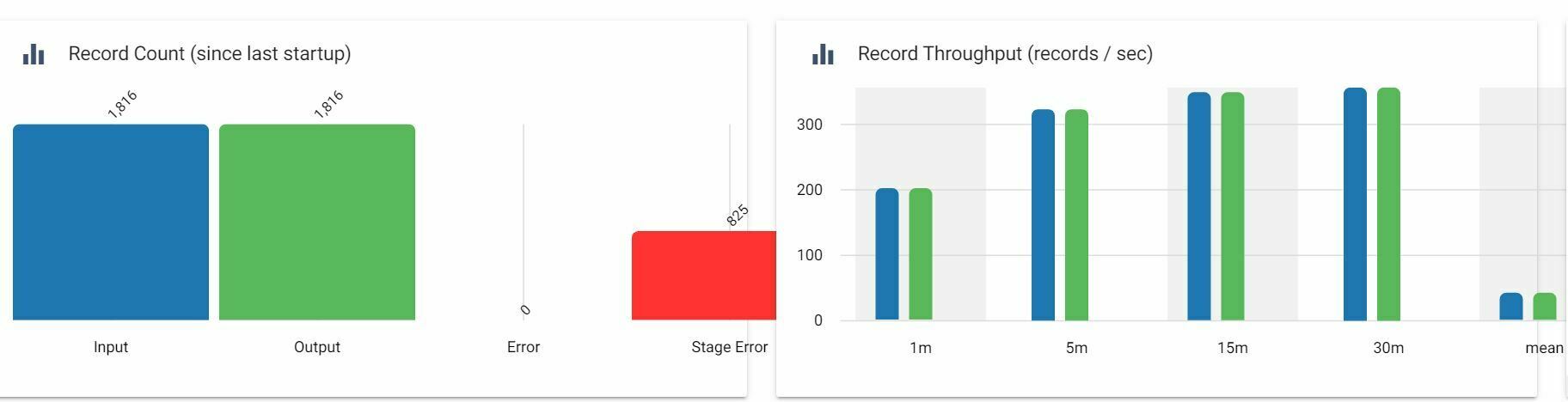
I’m trying to write some simple output from a database to an Amazon S3 bucket. I have the access key and shared secret setup properly, but what values do I need to use for bucket and path? The documentation isn’t too clear and the rows seem to all go to Stage Error on a pipeline run.







Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.