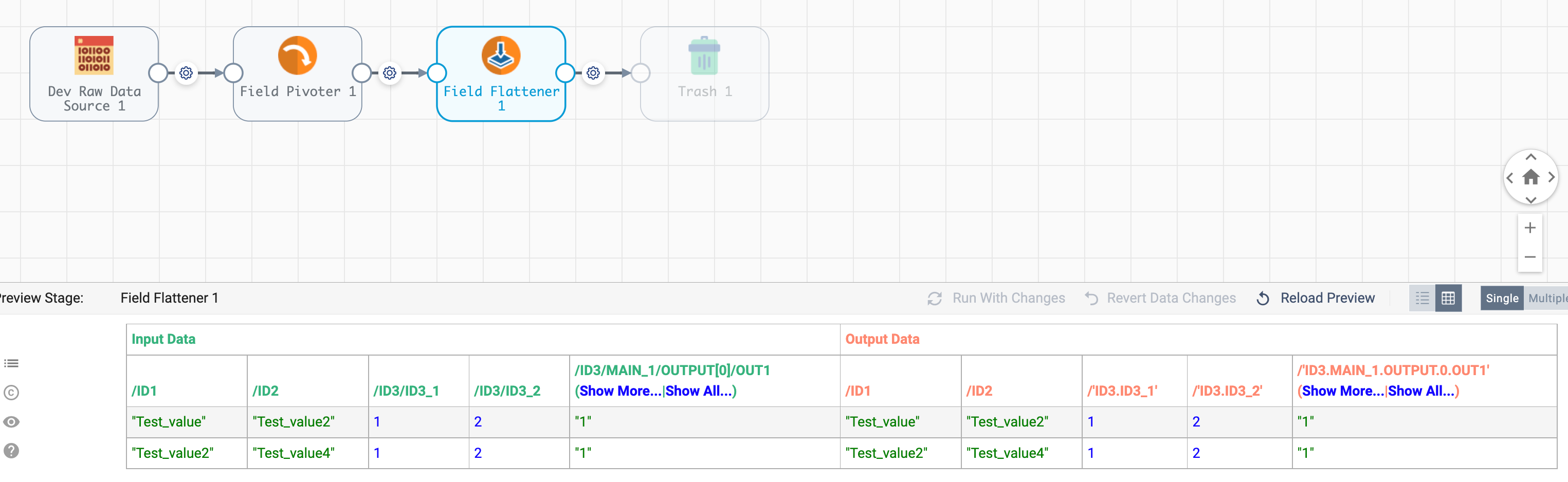
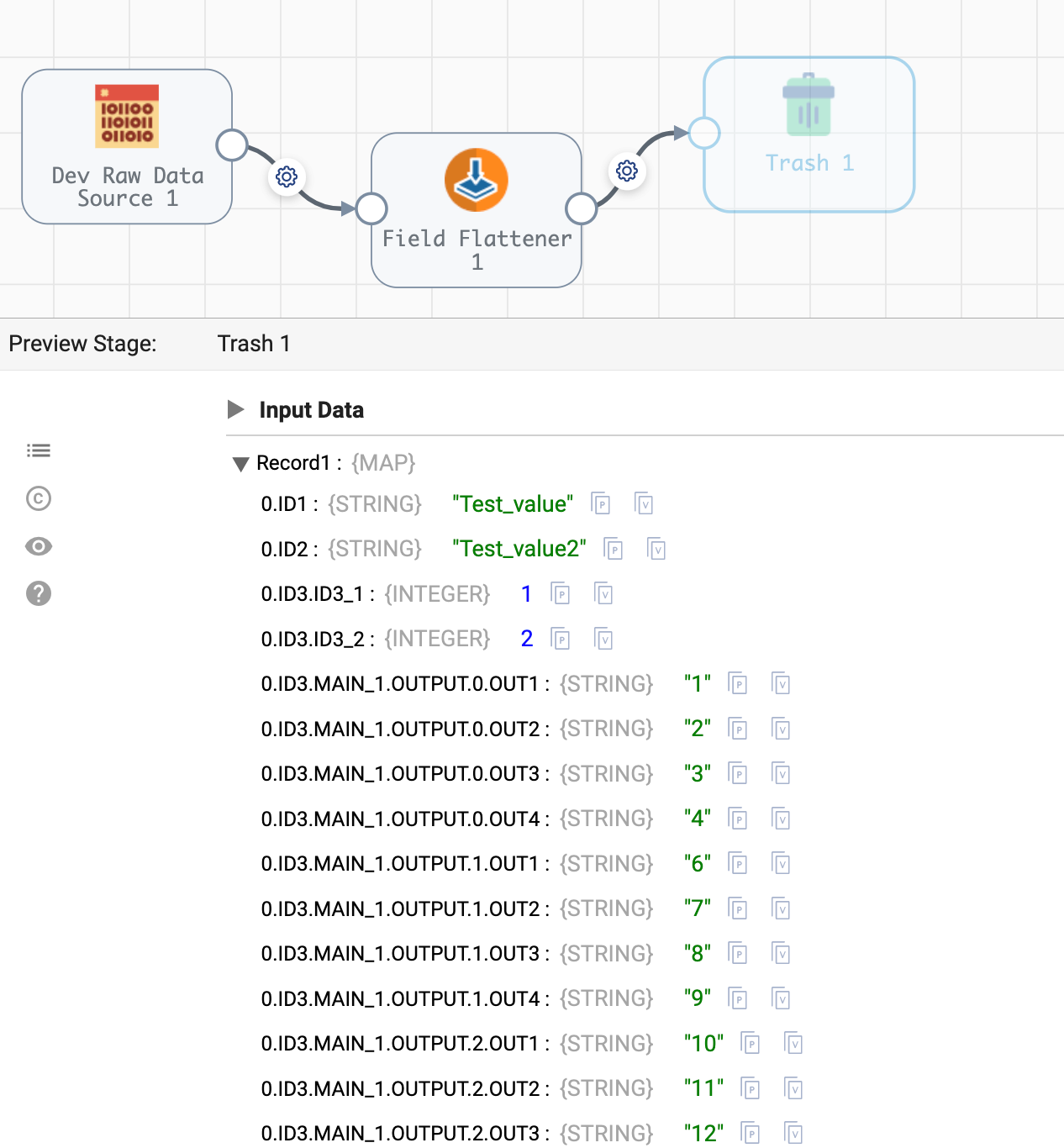
Hello Team,
Could you please assist me with below JSON flattening,
[
{
"ID1": "Test_value",
"ID2": "Test_value2",
"ID3": {
"ID3_1": 1,
"ID3_2": 2,
"MAIN_1": {
"OUTPUT": [
{
"OUT1": "1",
"OUT2": "2",
"OUT3": "3",
"OUT4": "4"
},
{
"OUT1": "6",
"OUT2": "7",
"OUT3": "8",
"OUT4": "9"
},
{
"OUT1": "10",
"OUT2": "11",
"OUT3": "12",
"OUT4": "13"
}
]
},
"MAIN_2": {
"OUTPUT": [
{
"OUT1": "1",
"OUT2": "2",
"OUT3": "3",
"OUT4": "4"
},
{
"OUT1": "6",
"OUT2": "7",
"OUT3": "8",
"OUT4": "9"
},
{
"OUT1": "10",
"OUT2": "11",
"OUT3": "12",
"OUT4": "13"
}
]
},
"MAIN_3": {
"OUTPUT": [
{
"OUT1": "1",
"OUT2": "2",
"OUT3": "3",
"OUT4": "4"
},
{
"OUT1": "6",
"OUT2": "7",
"OUT3": "8",
"OUT4": "9"
},
{
"OUT1": "10",
"OUT2": "11",
"OUT3": "12",
"OUT4": "13"
}
]
}
}
}
]
Expected Output :
| ID1 | ID2 | ID3.ID3_1 | ID3.ID3_2 | ID3.MAIN_1.OUTPUT.OUT1 | ID3.MAIN_1.OUTPUT.OUT2 | ID3.MAIN_1.OUTPUT.OUT3 | ID3.MAIN_1.OUTPUT.OUT4 | ID3.MAIN_2.OUTPUT.OUT1 | ID3.MAIN_2.OUTPUT.OUT2 | ID3.MAIN_2.OUTPUT.OUT3 | ID3.MAIN_2.OUTPUT.OUT4 |
Also, we have not fixed number of “MAIN_*” tags, it is not fixed.