



Dear Community users,
SDC offers a great out-of-box processor “Field Type Converter” to convert an incoming field of one data type to another data type. This is a very useful transformation function that is required before we send the data to final destination. However, sometime we may have to write our own transformation function and today I’m going to share a scenario where I was forced to use a jython evaluator to detect the date format of an incoming field and convert that to a single unified format that our destination is expecting.
Problem Statement
We have a need to process the incoming file where there is a field that need to be processed as “date” data type while there is another field which needs to be processed as “timestamp” data type before we generate the final feed for destination. The detaination while accepts the “date” fields is YYYY-MM-DD format, the timestamp fileds need to be of YYYY-MM-DD HH:MI:SS GMT+05:30, the origin fields can be of different formats. The solution must auto-detect the incoming date/timestamp format and convert that to a fixed destination format.
Solution Description
Unfortunately we couldn’t force our customer to send fields in the same format that our destination is expecting. Customer also said that there are multiple platforms that are responsible to generate the source file and due to some legacy, they all generate these fields in different format.
Since the incoming field format is not known, we had to implement a custom fuction in jython evaluator that can detect the incoming field format using regular expression and then convert that data to our desired format.
SDC Pipeline
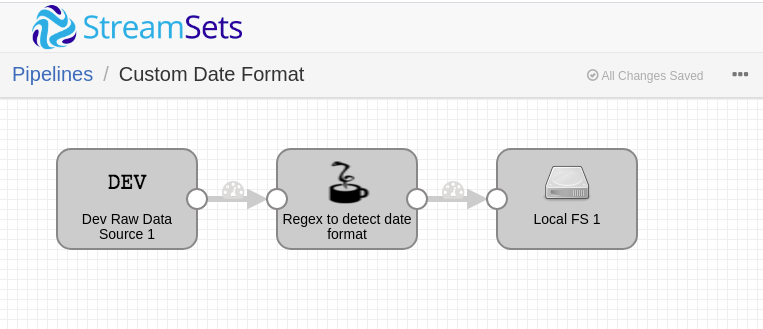
-
Dev Raw Data Source: For this small exercise, I’ve taken this origin as it’s easy for me to hard code the incoming data. You can see diferent date and timestamp formats here.
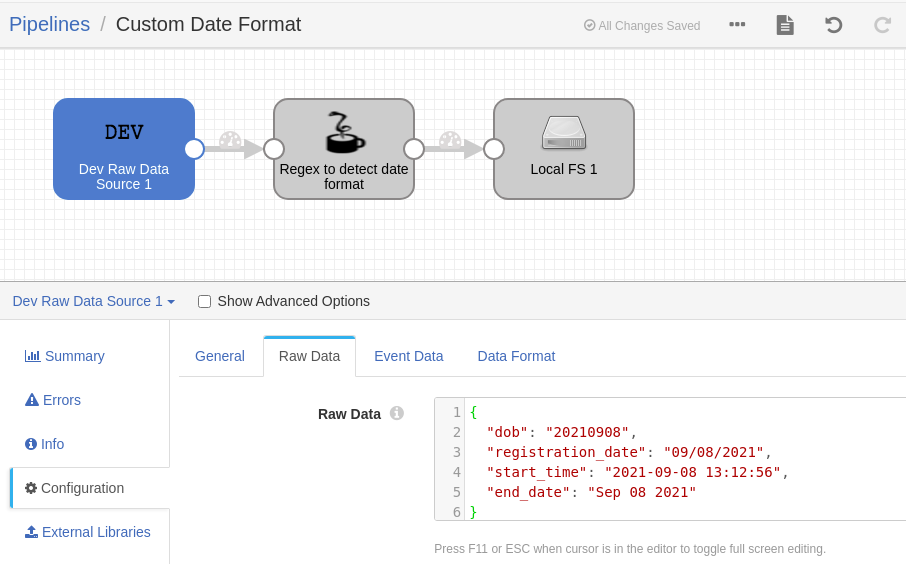
- Jython Evaluator: As you can see, there are different fields each in different format. We wrote the below script to detect the format using python regex and change it to our desired output format. (Please note that “timezone” is a parameter configured in pipeline to hold the value “GMT+05:30”).
import re
from datetime import datetime
def isBlank (myString):
log.info("***isBlank field: {} | ",myString)
return not (myString and myString.strip())
def isNotBlank (myString):
return bool(myString and myString.strip())
def outDate (line):
line = line.strip()
if isNotBlank(line):
dateObj = None
if re.match(r"^\d{8}$", line):
dateObj = datetime.strptime(line,'%Y%m%d')
return (dateObj.strftime('%Y-%m-%d'))
elif re.match(r"^\d{1,2}/", line):
dateObj = datetime.strptime(line,'%m/%d/%Y')
return (dateObj.strftime('%Y-%m-%d'))
elif re.match(r"^[a-z]{3}[ ]{1,}\d{1,2}[ ]{1,}\d{4}[ ]{1,}\d{1,2}:\d{2}", line, re.IGNORECASE):
dateObj = datetime.strptime(line,'%b %d %Y %H:%M%p')
return (dateObj.strftime('%Y-%m-%d %H:%M:%S') + " ${timezone}")
elif re.match(r"^[a-z]{3} \d{1,2} \d{4} ", line, re.IGNORECASE):
dateObj = datetime.strptime(line,'%b %d %Y %H:%M%p')
return (dateObj.strftime('%Y-%m-%d'))
elif re.match(r"^[a-z]{3}[ ]{1,}\d{1,2}[ ]{1,}\d{4}", line, re.IGNORECASE):
dateObj = datetime.strptime(line,'%b %d %Y')
return (dateObj.strftime('%Y-%m-%d'))
elif re.match(r"^[a-z]{3}", line, re.IGNORECASE):
dateObj = datetime.strptime(line,'%b %d %Y')
return (dateObj.strftime('%Y-%m-%d'))
elif re.match(r"^\d{1,2} [a-z]{3}", line, re.IGNORECASE):
dateObj = datetime.strptime(line,'%d %b %Y')
return (dateObj.strftime('%Y-%m-%d'))
elif re.match(r"^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}", line):
dateObj = datetime.strptime(line,'%Y-%m-%d %H:%M:%S')
return (dateObj.strftime('%Y-%m-%d %H:%M:%S') + " ${timezone}")
elif re.match(r"^\d{4}-\d{2}-\d{2} \d{2}:\d{2}", line):
dateObj = datetime.strptime(line,'%Y-%m-%d %H:%M')
return (dateObj.strftime('%Y-%m-%d %H:%M:%S') + " ${timezone}")
elif re.match(r"^\d{4}-\d{2}-\d{2}", line):
dateObj = datetime.strptime(line,'%Y-%m-%d')
return (dateObj.strftime('%Y-%m-%d'))
for record in records:
try:
# Convert field to JSON
fields = ['dob', 'registration_date', 'start_time', 'end_date']
for field in fields:
if field in record.value:
record.value[field] = outDate(record.value[field])
# Write record to processor output
output.write(record)
except Exception as e:
# Send record to error
error.write(record, str(e))As you can see above, we have a series of regex patterns that we run based on the input fields. Once there is a pattern match, we have taken action to update the field with our desired pattern.
- Local FS: Just to write the final O/P into a destination.
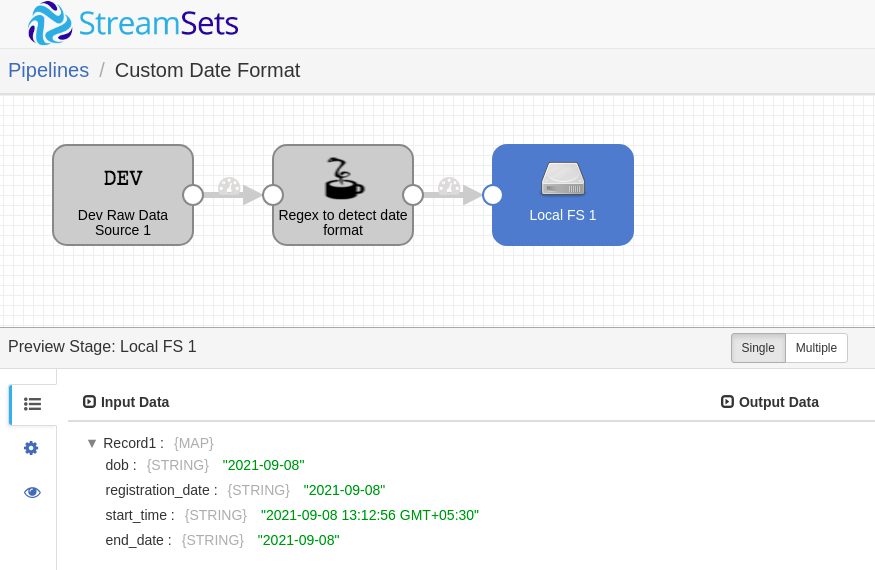
Conclusion
It’s always easy to work on predictable inputs based on an agreed specification and define your rules using out-of-box processors. However, sometime it’s not quite possible to have predictable fields/formats in place - and we have to develope custom rules to auto-discover the data format. SDC provides options to write such custom rules using external evaluators (Groovy, Jython, JS) and as demonstrated above, it’s easy to adopt them.
Let me know how you would like to implement the solution for the above example. If there are other better ways to achive this, it will be great to have them here.


