I am trying to capture change data from SQL Server database for which I have enabled the CDC for the source table in SQL Server database and loading the data to Snowflake destination in StreamSets, I am getting below error while running/previewing the pipeline in StreamSets Control Hub Platform. Please find the below error:
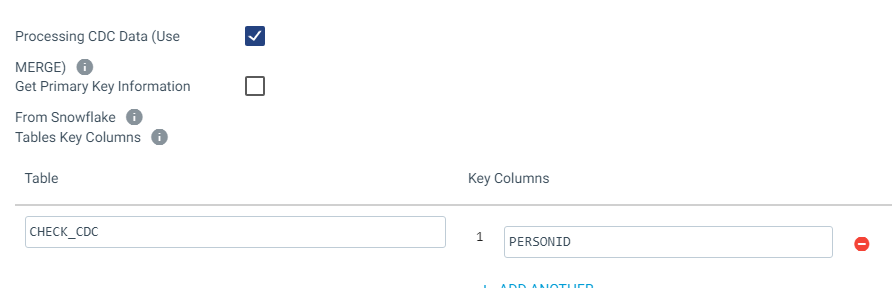
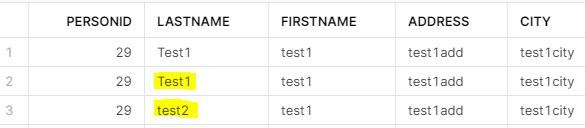
SNOWFLAKE_27 - CDC record is missing the ‘PERSONID’ key field
Note: PERSONID is the Primary key specified both in SQL Server and Snowflake tables
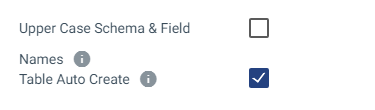
I tried with checking and unchecking the “Get Primary Key Information” option and similarly with table auto create option. But still, I am facing the same error. Could anyone please help me fix this issue. Thanks in advance. Happy to share more details if required.