Product: StreamSets Data Collector
Question:
When running a Hadoop Cluster batch process and Mapred stage in SDC can we pass a custom mapred-site.xml configuration from SDC pipeline.
In this case the default value of mapreduce.task.timeout is 600000 and we wanted to run the MR job with this value set to 200000.
One way to validate is the job config is dumped in the generated xml file of JHS.
hdfs dfs -get /user/^Cstory/done/2020/10/16/000000/*
/root@node-1 94-yarn-JOBHISTORY]# cat job_1602856174452_0001_conf.xml | grep -i mapreduce.task.timeout
<property><name>mapreduce.task.timeout</name><value>600000</value><final>false</final><source>mapred-site.xml</source><source>job.xml</source></property>Answer:
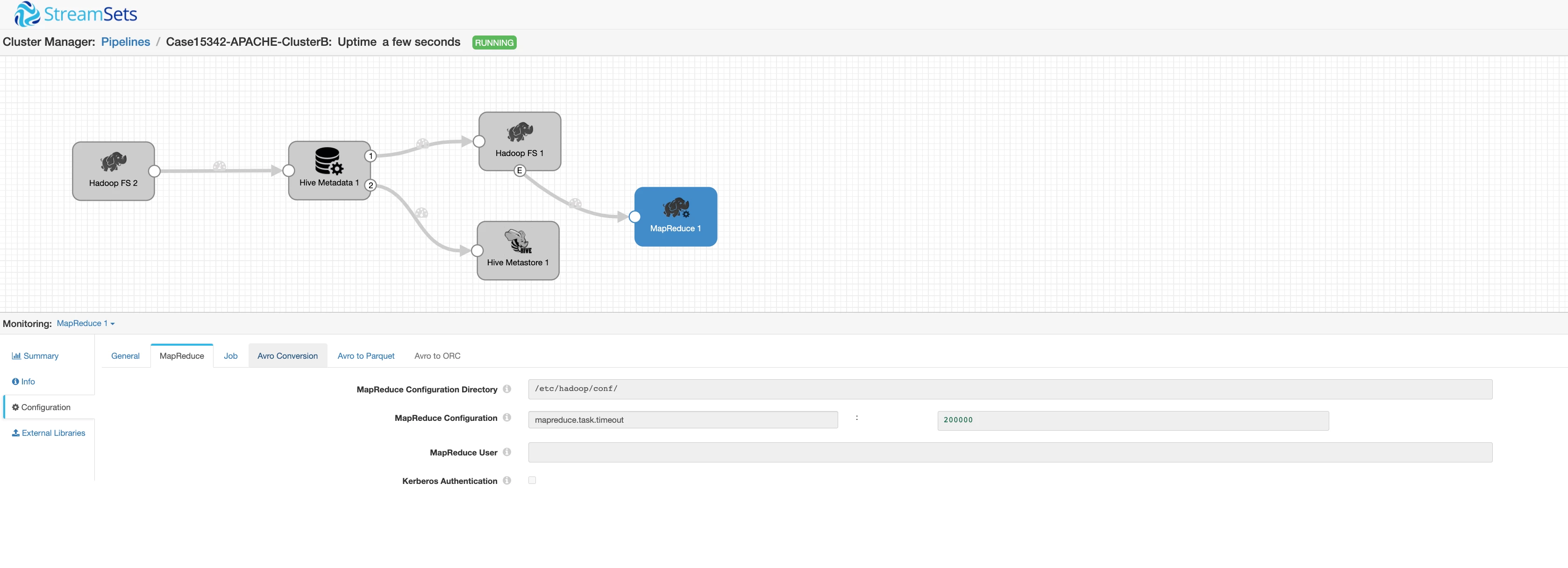
Please find the screenshots that describe how you can set MR parameters and please find the snippet below to validate that in your job
eroot@node-1 86-hdfs-NAMENODE]# hdfs dfs -get /user/history/done/2020/10/16/000000/* .
get: `job_1602856174452_0001-1602870975867-hive-insert+into+dbo+values+%28%27a1%27%29+%28Stage%2D1%29-1602870993928-1-0-SUCCEEDED-root.users.hive-1602870985998.jhist': File exists
get: `job_1602856174452_0001_conf.xml': File exists
get: `job_1602856174452_0002-1602885381377-sdc-StreamSets+Data+Collector%3A+Case15342%2DAPACHE%2DCluste-1602885426029-1-0-SUCCEEDED-root.users.sdc-1602885394665.jhist': File exists
get: `job_1602856174452_0002_conf.xml': File exists
get: `job_1602856174452_0003-1602886921764-sdc-StreamSets+Data+Collector%3A+Case15342%2DAPACHE%2DCluste-1602886971341-1-0-SUCCEEDED-root.users.sdc-1602886938098.jhist': File exists
get: `job_1602856174452_0003_conf.xml': File exists
root@node-1 86-hdfs-NAMENODE]# cat job_1602856174452_0005_conf.xml | grep -i mapreduce.task.timeout
<property><name>mapreduce.task.timeout</name><value>200000</value><final>false</final><source>programatically</source><source>job.xml</source></property>
root@node-1 86-hdfs-NAMENODE]#
root@node-1 86-hdfs-NAMENODE]#
root@node-1 86-hdfs-NAMENODE]#
root@node-1 86-hdfs-NAMENODE]#