



In this article, we will explore the process of creating a pipeline to transfer data from a MySQL database to a Delta Lake tables on Databricks.
Environment:
- Data Collector on DataOps platform.
- Destination Databricks Delta Lake.
These are the steps we need to follow to develop the pipeline:
- Login to Databricks UI » Compute » Create new compute then fill out all the details such as spark version, type of cluster, worker type. Once everything is finalised, click on create compute.
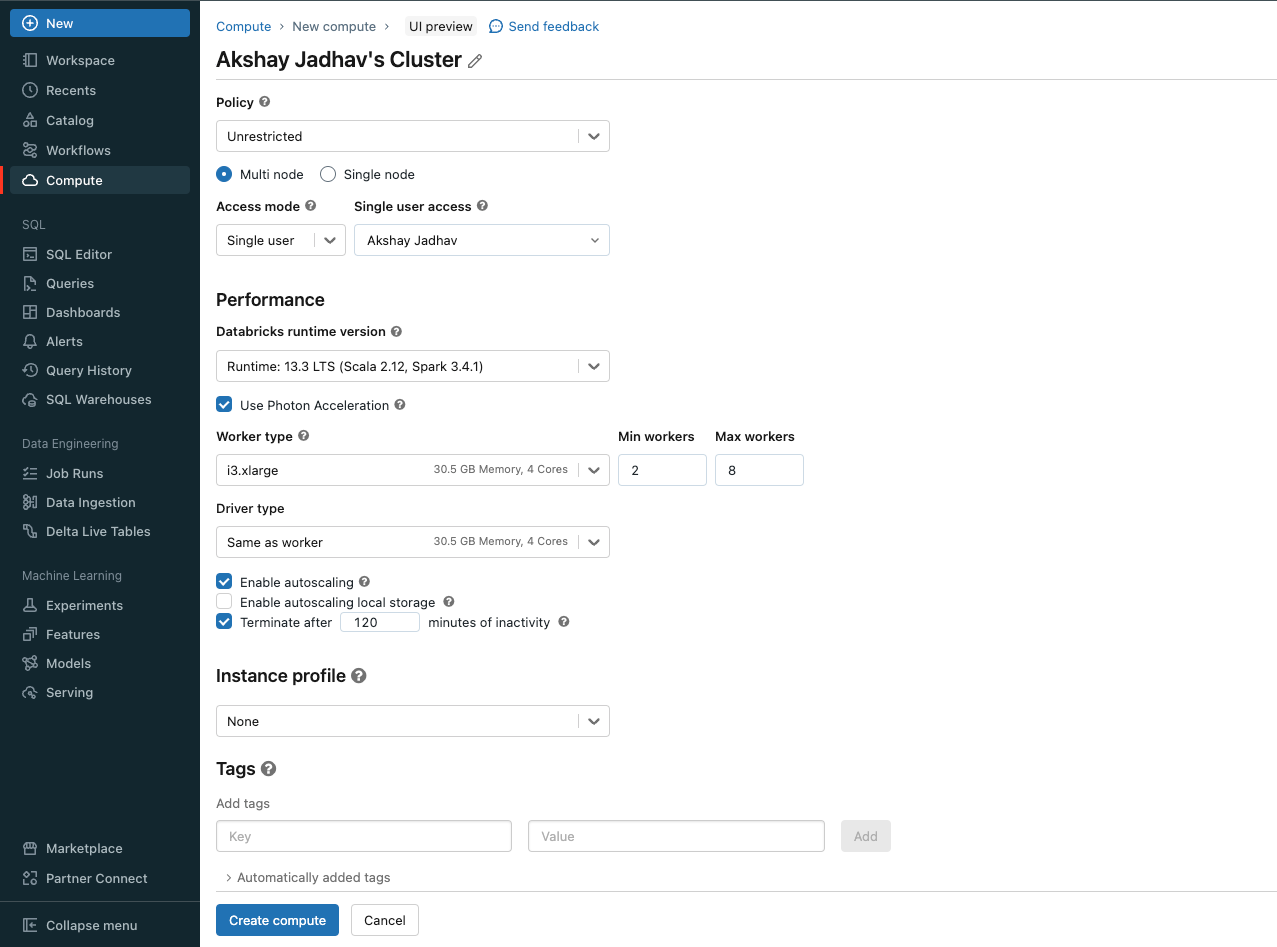
- Now, we will have to fetch the following information from the cluster and populate into the pipeline configuration section.
- Token: In your Databricks workspace, click your Databricks username in the top bar, and then select User Settings from the dropdown » Develop » Token » Generate a new token.
- JDBC String: Click on the Databricks newly created cluster, scroll down and expand Advance Option tab » JDBC/ODBC.
- For staging purpose, we need to use AWS S3, Google Storage or Azure ADLS. I am going to use the Google Storage in this testing.
After collecting all the necessary details, you can populate them into the Databricks Delta Lake destination and perform a validation of the pipeline prior to execution.
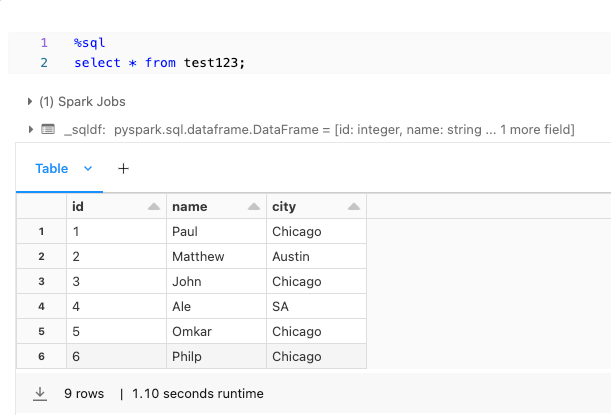
Here is a method to confirm the successful data write to the destination. In the screenshot below, you can see that only the first 6 records are visible in the UI. You also have the option to download the record files containing all the table's records.
Attaching the data collector pipeline for references.
[2]. https://docs.databricks.com/en/getting-started/quick-start.html