


I wanted to have a way to send chess game information from lichess.org (a popular chess server) to Elasticsearch and Snowflake to let me visualize statistics (e.g., how often does World Champion GM Magnus Carlsen lose to GM Daniel Naroditsky?) as well as to generate reports in Snowflake (e.g., when Magnus does lose, which openings does he tend to play?). I ended up accomplishing this with two pipelines:
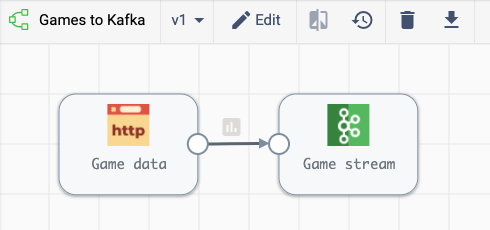
This pipeline is a batch pipeline that ingests data using the lichess REST API and pushes it to a Kafka topic. It uses an endpoint that allows for pulling down all games by username, so I’ve parameterized the username portion and then can use Control Hub jobs to pick which specific users I want to study.
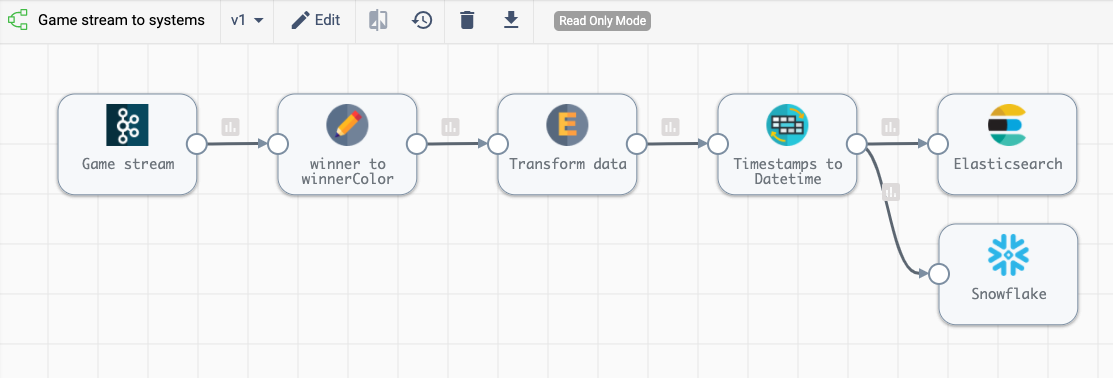
This pipeline consumes game data from my Kafka topic, does some basic cleanup of the data (adds a field for the name of the winner rather than the color of the winning pieces and converts timestamps from long to datetime) as well as some basic enrichment (it adds a field that calculates how long the game took) before sending it off to Elasticsearch and Snowflake. Since this pipeline is streaming, it runs all the time, ready to process new data when I stumble upon interesting games or players.

