



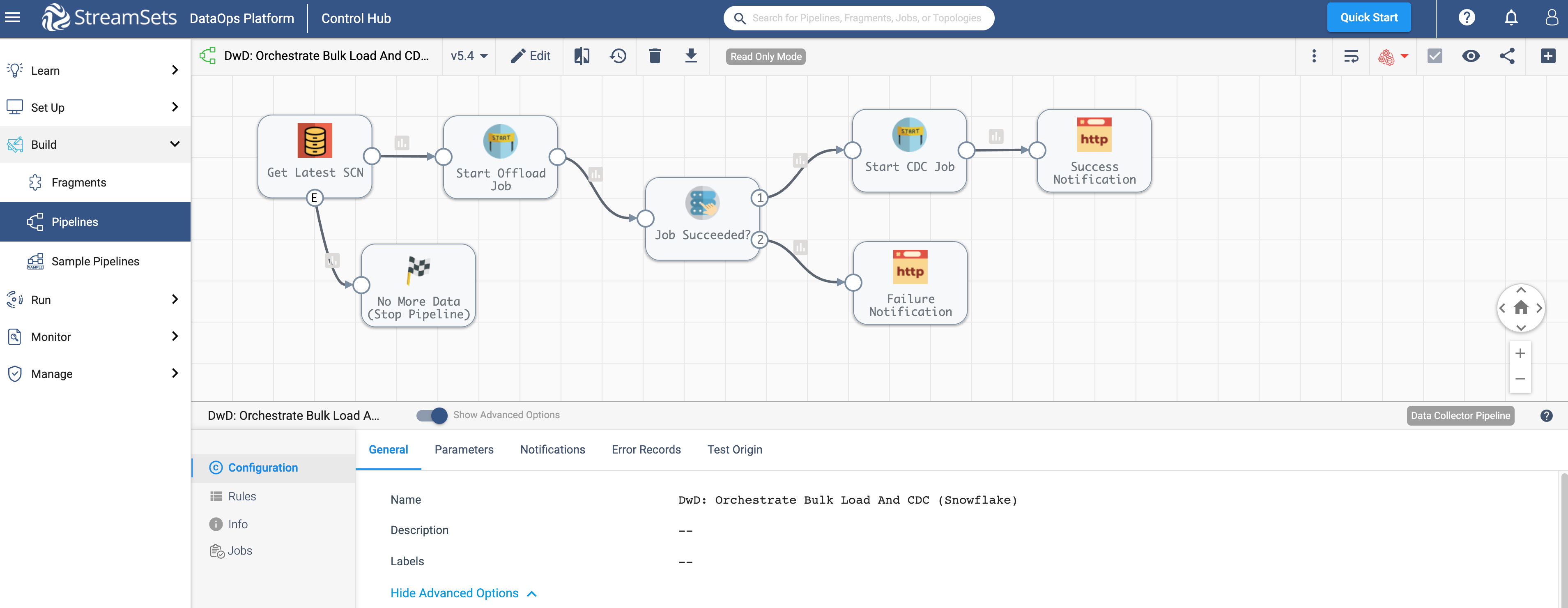
This pipeline is designed to orchestrate initial bulk load to change data capture workload from on-prem Oracle database to Snowflake Data Cloud. The pipeline takes into consideration the completion status of the initial bulk load job before proceeding to the next (CDC) step and also sends success/failure notifications. The pipeline also takes advantage of the platform’s event framework to automatically stop the pipeline when there’s no more data to be ingested.

