Trying to build data pipeline for Azure SQL Server DB (CDC) as source and Azure Data bricks (Delta tables) as destination
I have referred data pipeline sample from
https://github.com/streamsets/pipeline-library/tree/master/datacollector/sample-pipelines/pipelines/SQLServer%20CDC%20to%20Delta%20Lake
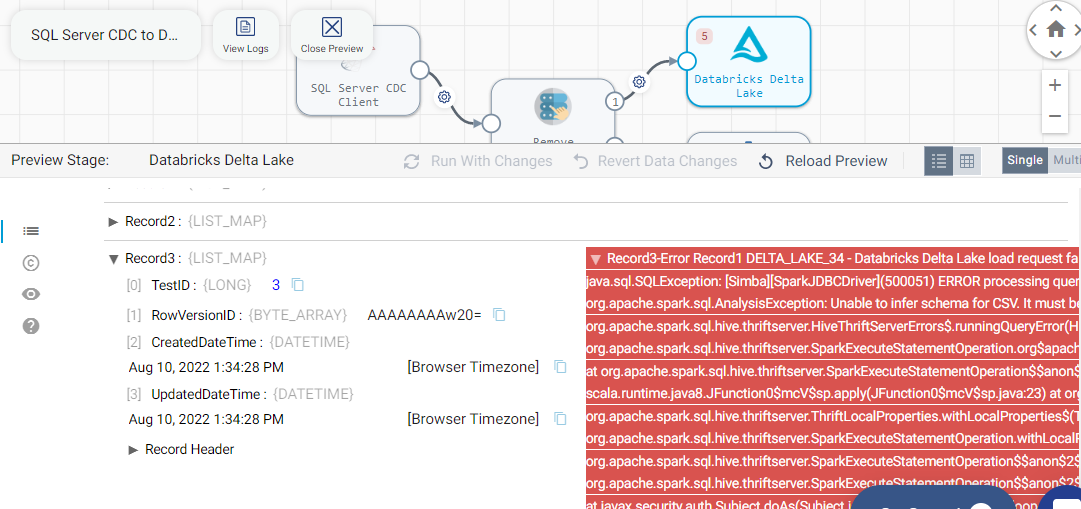
Getting below error for few records in Schema preview as-well:
DELTA_LAKE_34 - Databricks Delta Lake load request failed: 'DELTA_LAKE_32 - Could not copy staged file 'sdc-4a076fce-7a73-45ba-8dd7-29e58848cf23.csv': java.sql.SQLException: [Simba][SparkJDBCDriver](500051) ERROR processing query/statement. Error Code: 0, SQL state: org.apache.hive.service.cli.HiveSQLException: Error running query: org.apache.spark.sql.AnalysisException: Unable to infer schema for CSV. It must be specified manually.
Note : On Preview/Draft Run → Pipeline is able to capture changes from Source DB, successfully created files in stage (ADLS container) and created Delta tables at destination but it it fails to ingest records there.