



In this article, we will review two basic scenarios.
- Impersonation in transformer without Kerberos
- Impersonation in transformer with Kerberos
Before we jump to any scenario their are few pre-requisite steps which we need to follow
Transformer Proxy Users Prerequisite
When using a Hadoop YARN cluster manager, the following directories must exist:
1. Spark node local directories
The Spark yarn.nodemanager.local-dir configuration parameter in the yarn-site.xml file defines one or more directories that must exist on each Spark node.
The value of the configuration parameter should be available in the cluster manager user interface. By default, the property is set to ${hadoop.tmp.dir}/nm-local-dir.
The specified directories must meet all of the following requirements for each node of the cluster:
- Exist on each node of the cluster.
- Be owned by YARN.
- Have read permission granted to the Transformer proxy user.
2. HDFS application resource directories
Spark stores resources for all Spark applications started by Transformer in the HDFS home directory of the Transformer proxy user. Home directories are named after the Transformer proxy user, as follows:
/user/<Transformer proxy user name>Ensure that both of the following requirements are met:
- Each resource directory exists on HDFS.
- Each Transformer proxy user has read and write permission on their resource directory.
For example, you might use the following command to add a Transformer user, rishi, to a spark user group:
usermod -aG spark rishiThen, you can use the following commands to create the /user/rishi directory and ensure that the spark user group has the correct permissions to access the directory:
sudo -u hdfs hdfs dfs -mkdir /user/rishi
sudo -u hdfs hdfs dfs -chown rishi:spark /user/rishi
sudo -u hdfs hdfs dfs -chmod -R 775 /user/rishiNow let's explore each scenario
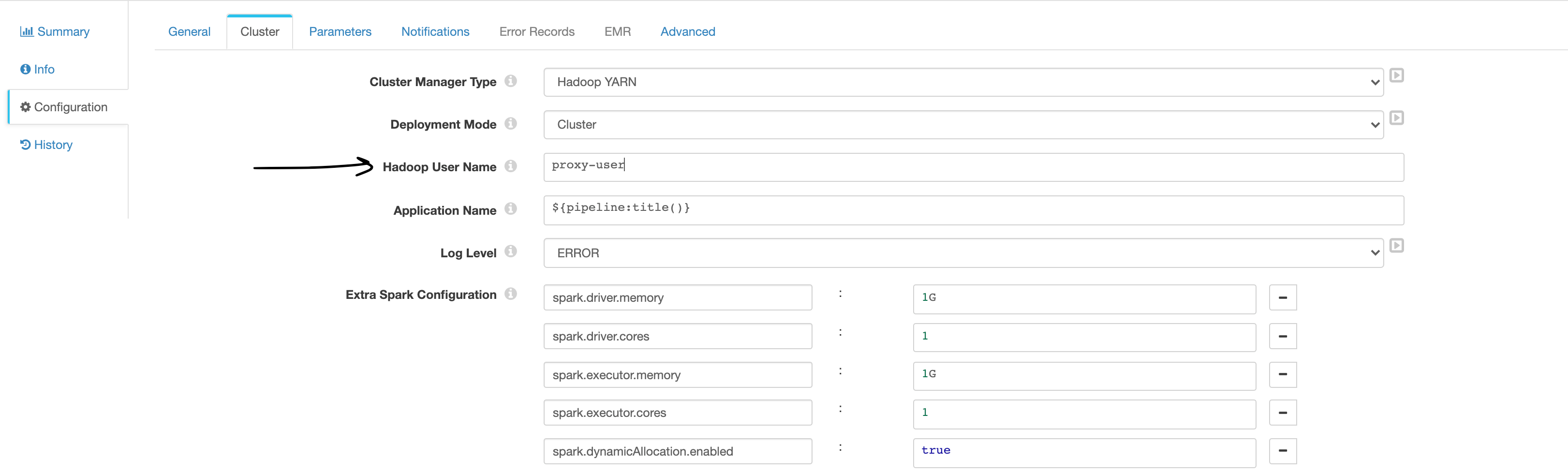
- Impersonation without Kerberos: This one is very straightforward and doesn't require many changes.
As the user-defined in the pipeline properties - When configured, Transformer uses the specified Hadoop user to launch the Spark application and to access files in the Hadoop system.
- Impersonation with Kerberos
This is the scenario where it became a bit complex. We will try to deep dive and try to understand how this works.
So the Transformer allows you two options to specify the keytab/principal

1. Properties file:
When a pipeline uses the properties file as the keytab source, the pipeline uses the same Kerberos keytab and principal configured for Transformer in the Transformer configuration file, $TRANSFORMER_DIST/etc/transformer.properties.
For information about specifying the Kerberos keytab in the Transformer configuration file, see Enabling the Properties File as the Keytab Source.
2. Pipeline configuration:
When a pipeline uses the pipeline configuration as the keytab source, you define a specific Kerberos keytab file and principal to use for the pipeline. Store the keytab file on the Transformer machine. In the pipeline properties, you define the absolute path to the keytab file and the Kerberos principal to use for that key
Default Behaviour :
When using a keytab, Transformer uses the Kerberos principal to launch the Spark application and to access files in the Hadoop system.
Note: Transformer ignores the Hadoop user defined in the pipeline properties
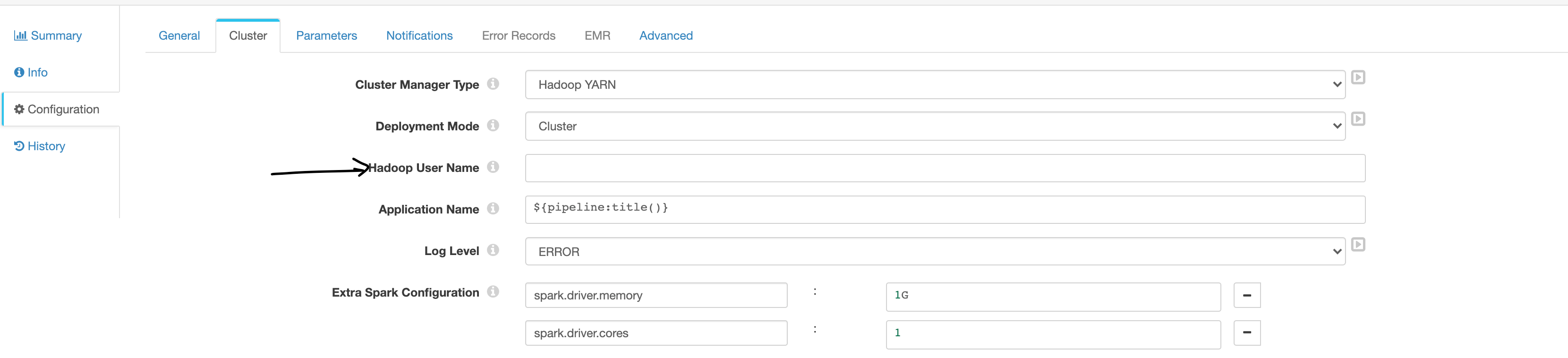
So now we know the default behavior, How to run a transformer job as logged in user for example you logged in as the desired proxy user in transformer ( i.e rishi). And our end goal is that we want to run this job as a user.
- Transformer Side Changes
1. Enable the hadoop.always.impersonate.current.user property in the Transformer configuration file, $TRANSFORMER_DIST/etc/transformer.properties
2. Before pipelines can use proxy users with Kerberos authentication, you must install the required Kerberos client packages on the Transformer machine and then configure the environment variables used by the K5start program.
Tip: Spark recommends using a Kerberos principal and keytab rather than a proxy user. To require that pipelines be configured with a Kerberos principal and keytab, do not enable proxy users.
- On Linux, install the following Kerberos client packages on the Transformer machine:
krb5-workstationkrb5-clientK5start, also known askstart-
#Add the epel repo to yum
$ yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm -
$ yum install kstart.x86_64
- the keytab file that contains the credentials for the Kerberos principal to the Transformer machine.
- Add the following environment variables to the Transformer environment configuration file.
Modify environment variables using the method required by your installation type.
| Environment Variable | Description |
|---|---|
| TRANSFORMER_K5START_CMD | Absolute path to the K5start program on the Transformer machine. |
| TRANSFORMER_K5START_KEYTAB | Absolute path and name of the Kerberos keytab file copied to the Transformer machine. |
| TRANSFORMER_K5START_PRINCIPAL | Kerberos principal to use. Enter a service principal. |

- Restart Transformer.
If you are wondering why we are doing this then let's understand this:
Background:
The --proxy-user argument to spark-submit allows you to run a Spark job as a different user, besides the one whose keytab you have.
That said, the recommended way of submitting jobs is always to use the --principal and --keytab options. This allows Spark to both keep the tickets updated for long-running applications, and also seamlessly distribute the keytab to any nodes that happen to need it (i.e. if they are spinning up an executor).
It is possible to use --proxy-user with Transformer. and the way we achieve this via k5start.
k5start : It takes care of obtaining a ticket from the KDC (like kinit), but it also refreses the token periodically based on the parameters, similar to what SecurityContext in Data Collector does. However, unlike SecurityContext, it writes to a ticket cache and keeps that cache updated as tickets expire, so that child processes (like spark-submit) can always get the latest version.
Validation Test:
1. Login with the desired proxy user in transformer
2. Create Test pipeline ( Dev Raw Data --> Trash )
3. No need to change anything at pipeline level Now.
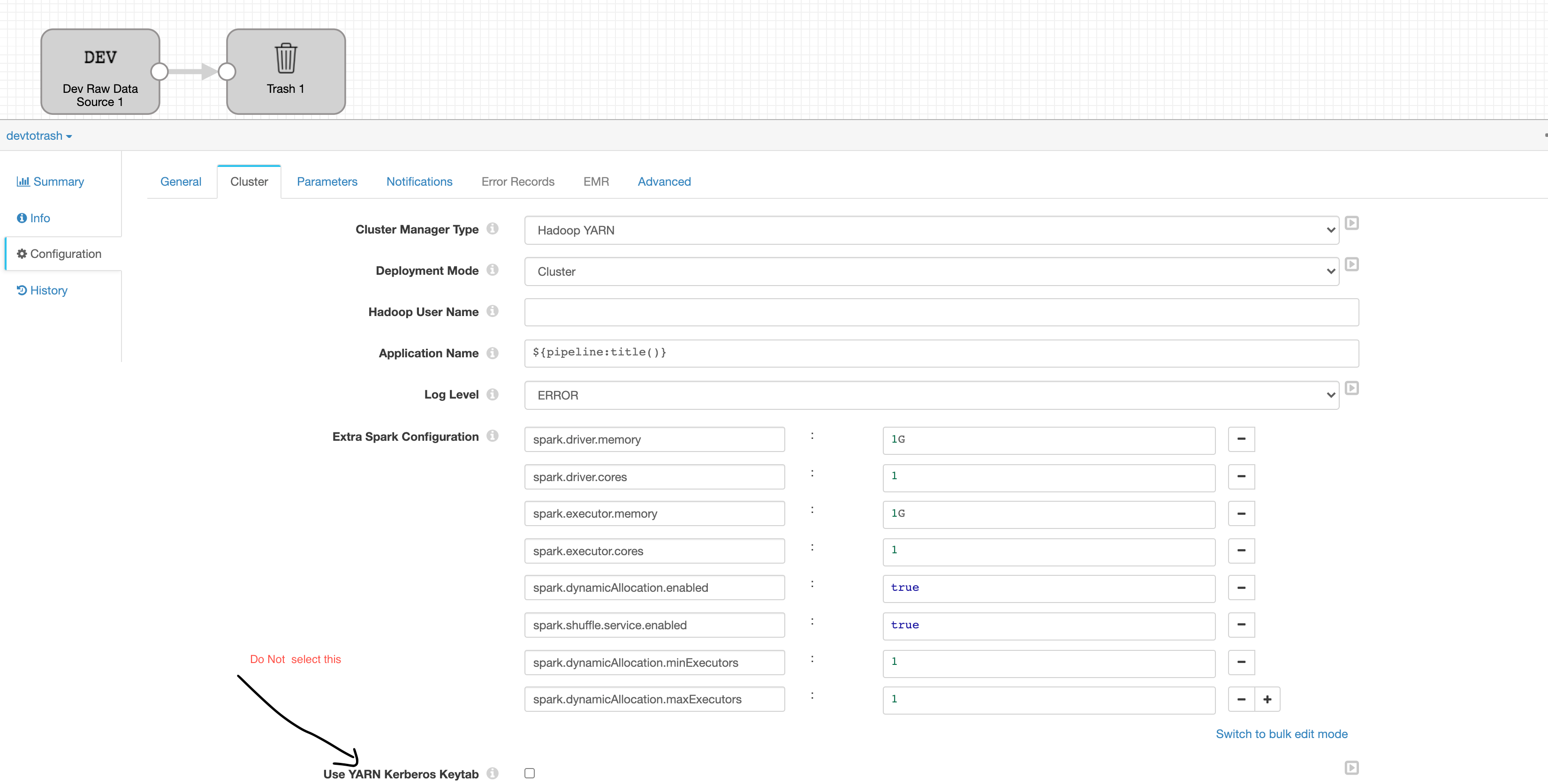
4. Run this job and. check the corresponding jobs in yarn. it should be submitted as a proxy user now.
Few Caveats
Pipelines fail to start when the following combination of things are all true:
- The cluster is Kerberized and uses YARN
- The transformer has been configured to use impersonation, and the user has configured the pipeline without specifying a keytab (meaning, impersonate the currently logged in user, provided that hadoop.always.impersonate.current.user=true)
- The pipeline is run in CLUSTER deploy mode
Workaround: Run in CLIENT mode || This issue has been fixed in 3.15
How to Troubleshoot?
- One quick way to verify is by using proxy-user arg with cluster mode, for SparkPi (or any example job), as a sanity check.
first, run kinit to initialize the user from keytab (the principal that would run Transformer)
next, for CDH 6.xspark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-memory 1G \
--proxy-user rishi \
--num-executors 1 \
--conf spark.hadoop.ipc.client.connect.max.retries=1 \
/opt/cloudera/parcels/CDH/lib/spark/examples/jars/spark-examples_*.jar 1000In the example command above, they would need to replace "rishi" with the actual logged-in user name they are trying to impersonate. This will trigger the same flow that is performed by a Transformer when doing an impersonation.