



Issue:
Due to some details on how Spark and HDFS work there is a problem when closing some files:
If a user stops manually a pipeline the last couple of files written to HDFS are not closed and they are kept with _tmp at the beginning of the name.
Some details about the behavior of HDFS in Spark streaming mode:
- the pipeline closes the files on the second run only after it starts processing and writing new records
- it does not convert some files if the pipeline starts on different Spark executors (they remain _tmp) - e.g. if you are reading from Kafka topic with more than one partition
- it does not convert files from different Hive partitions (different path to the files)
Versions affected:
The workaround is only valid for SDC 3.8.0 versions and above.
Workaround:
As a workaround, we can use another pipeline which will read the _tmp files and properly rename them. This pipeline needs minimum SDC version 3.8.0 to work, from that version we added to the HDFS Standalone origin the ability to read hidden files with Whole File Format ( files starting with _tmp would be classified as hidden files).
As an example of pipeline we could use (please, find the pipeline attached)
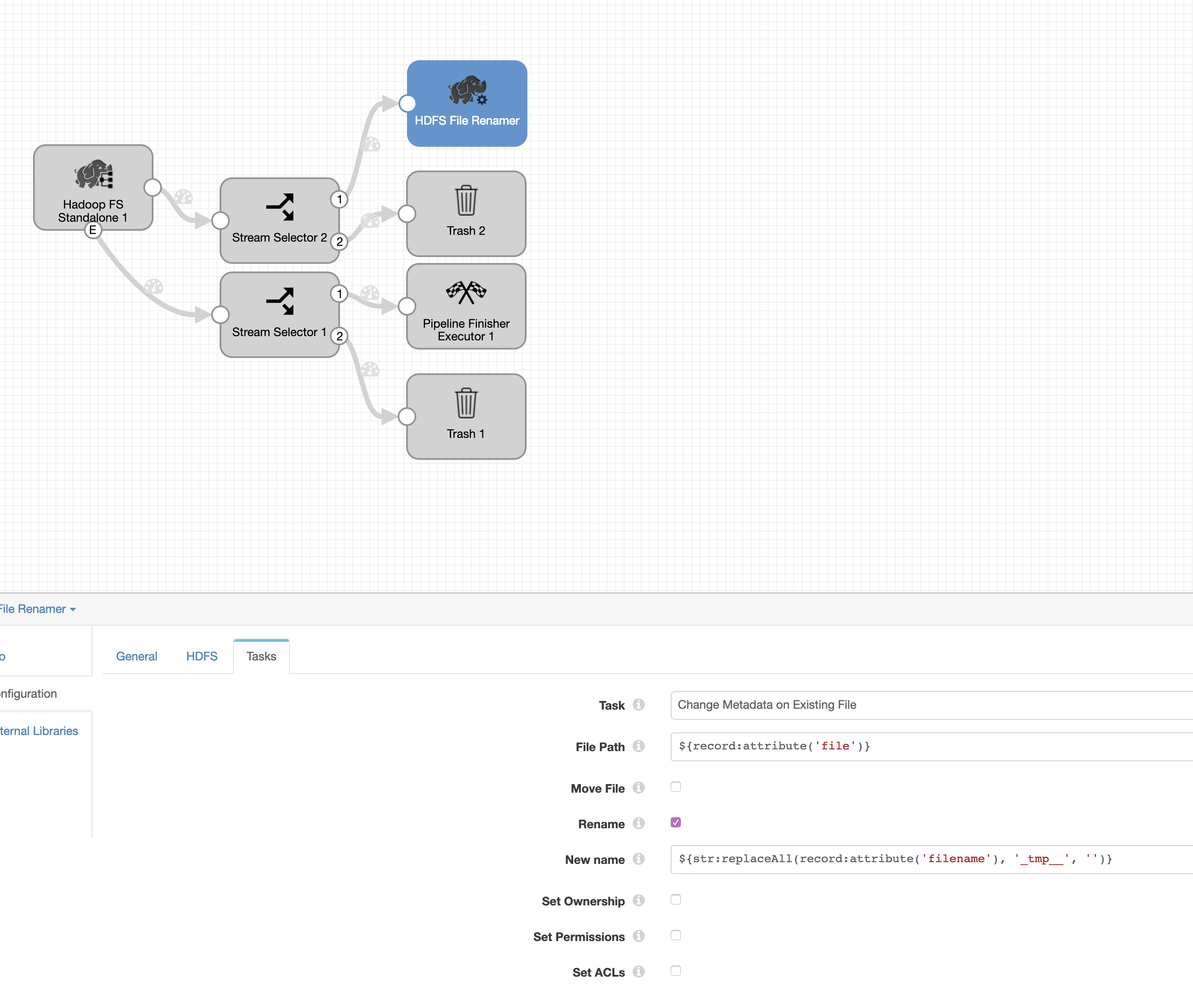
And configure the pipeline to be executed on a schedule with SCH scheduler with the desired Cron Expression.