


This document aims to explain how to create a pipeline with an origin configuration capable of ingesting multiple types of data format files in the DataOps platform. Once the pipeline is built, we will be able to create a job template capable of generating job instances for the desired data format ingestion.
This methodology works on any stage capable of ingesting multiple types of data. For explanatory purposes we are going to use Amazon S3 as an example to show how to set up the model.
First, we create the Pipeline:
-
Create the pipeline: create a pipeline with an origin S3 stage
-
Configure the origin S3 stage: Click on S3 stage > Configuration > Amazon S3 tab. Configure it to be able to connect to the desired server and bucket (it can also be parameterized if desired).
-
Parameterize the Data Format and Options:
-
Set the names of the parameters we want to use for data format: Click on the canvas > click on show advanced options > configuration > Parameters tab
-

-
Set the parameters we will use for data format: click on the origin S3 stage > Configuration > data format tab. The main issue when facing this task is that options for each of the data formats disappear as soon we set the parameter for the Data Format value. For example, delimited data format has options like Header Line or Delimiter Format Type. These options do not show anymore as soon as we introduce a parameter for the Data Format value (and therefore they cannot be parameterized). To parameterize these options, we must first set the parameters for each of the data format options (changing between Data Formats in the drop-down list) and then set the parameter for the data format value. Despite the parameterized options disappearing, they keep their parameters assigned and therefore their values can be set up when launched from a job.
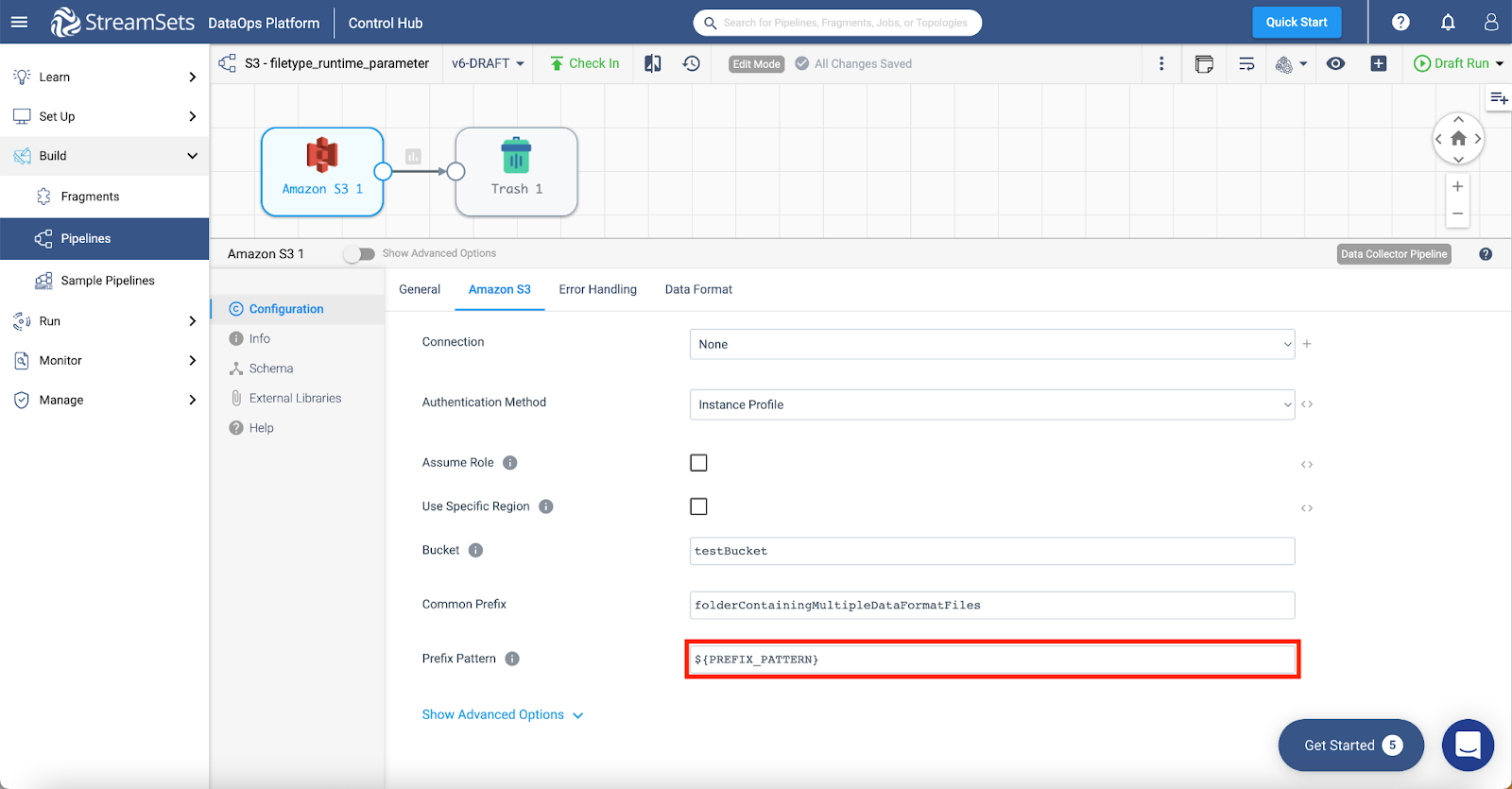
Finally we have to set the type of file we will be reading. This can be achieved by parameterizing Prefix Pattern under Amazon S3 tab. This parameter can be set to the name of the file extension to filter the files (example: “*.csv”).
Example: The following images show in 5 steps how to configure the stage for Delimited and XML data formats with options:
Step 1: Parameterize delimited options:

Step 2: Go to XML in the data format drop-down list:
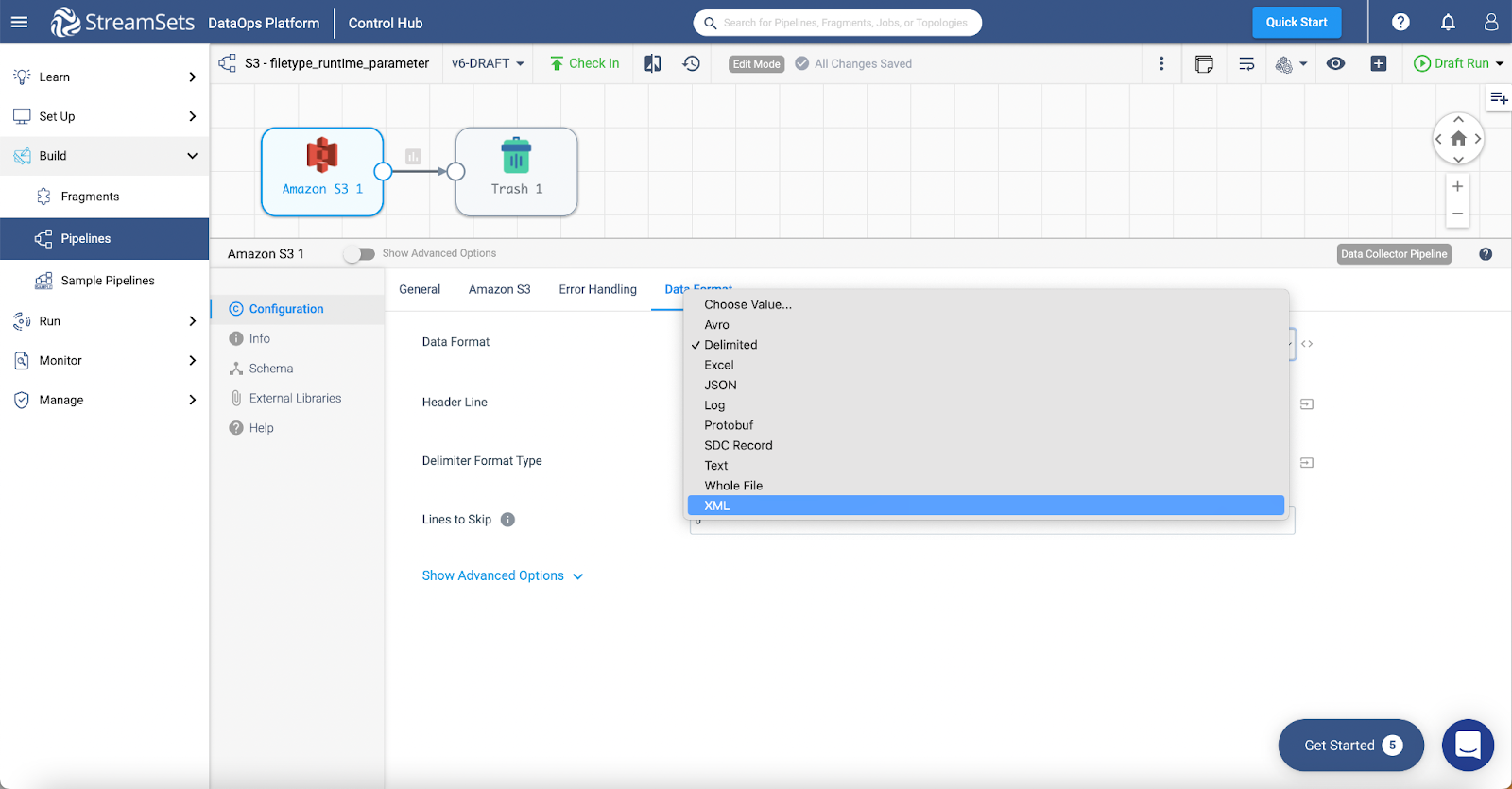
Step 3: Parameterize XML options:
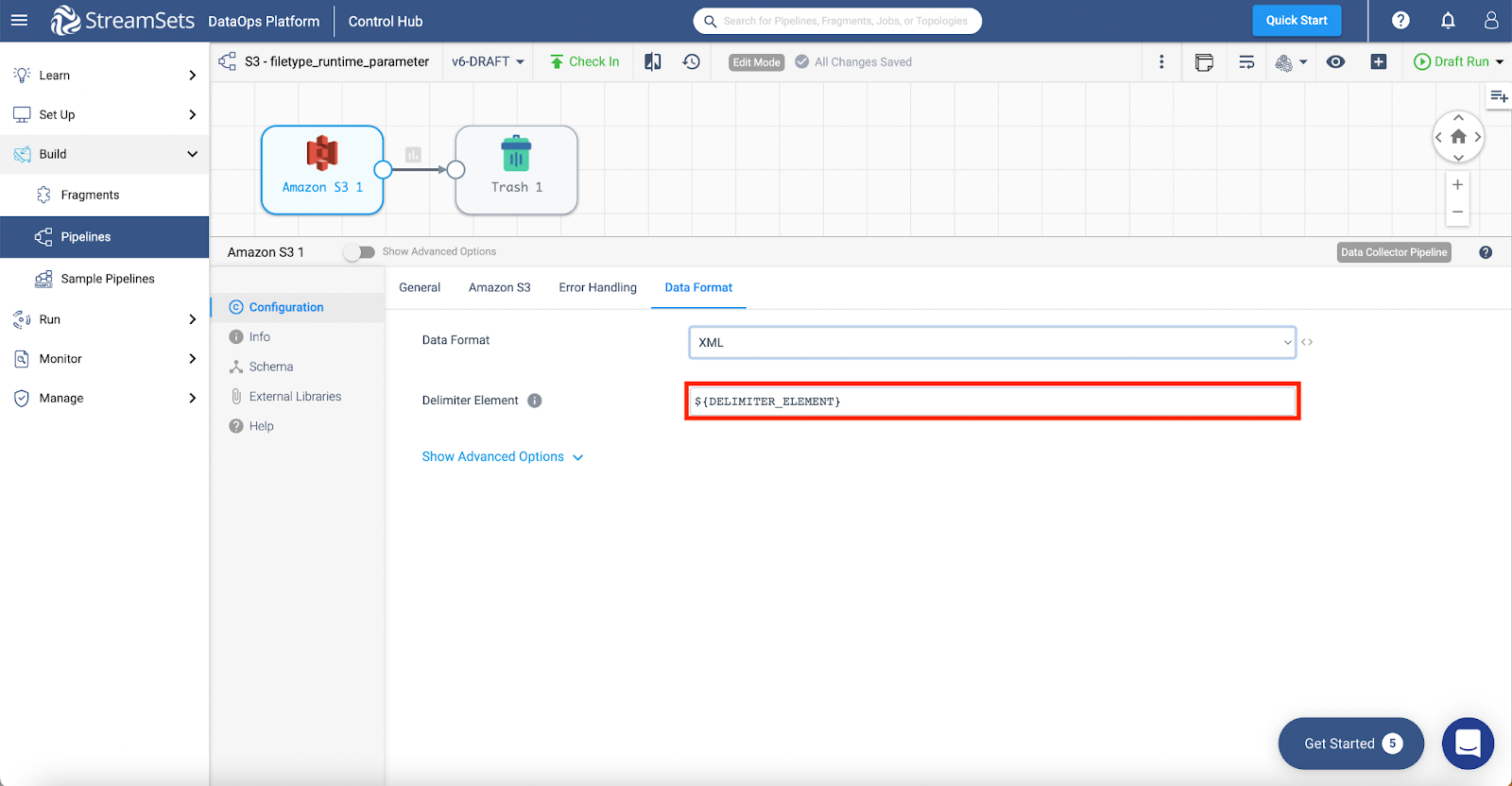
Step 4: Parameterize data format. Notice that as you do so, the options for any data format disappear
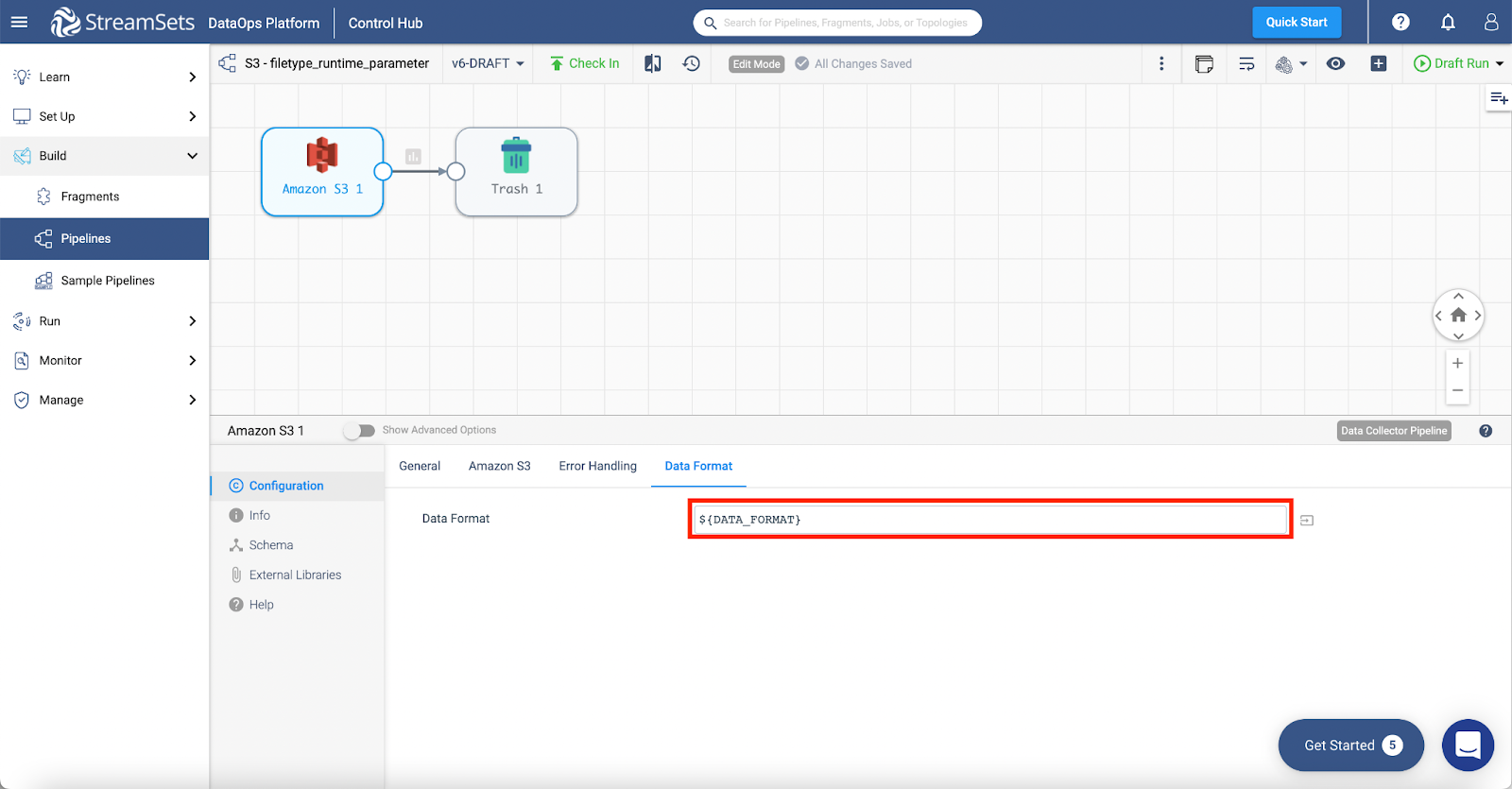
Step 5: Finally create the parameter for Prefix Pattern which will help us filter the income data using the file extension.
Secondly, we create the Job Template:
The job will be created using the normal procedure. Here we can set the desired default parameter values for the job instances.
Finally, we create Job Instances from our Job Template:
Now we can create job instances from our job template using the normal procedure. The parameters can be set (or modified from default values) during its creation configuration. Moreover, it is possible to create multiple job instances at once with different parameter values. To do so, in “Define Runtime Parameters” in job instance creation we will set up parameters as “bulk edit” or “from file”. We can create multiple job instances by introducing a text with the following structure or uploading it using a JSON format file:
[
{
"PARAM1_JOB1": "param1_job1_value",
"PARAM2_JOB1": "param2_job1_value",
. . .
"PARAMn_JOB1": "paramn_job1_value"
},
{
"PARAM1_JOB2": "param1_job2_value",
"PARAM2_JOB2": "param2_job2_value",
. . .
"PARAMn_JOB2": "paramn_job2_value"
},
{
. . .
},
{
"PARAM1_JOBm": "param1_jobm_value",
"PARAM2_JOBm": "param2_jobm_value",
. . .
"PARAMn_JOBm": "paramn_jobm_value"
}
]
Where m is the number of jobs that we want to create and n is the parameter number for a given job. When dealing with multiple data formats it is only necessary to pass the options parameters for that data format (given that the other options will not be used).