Hi Team,
I am trying to read the files from AWS S3 using the Amazon S3 origin. It does read the file at first level but doesn’t read the file recursively.
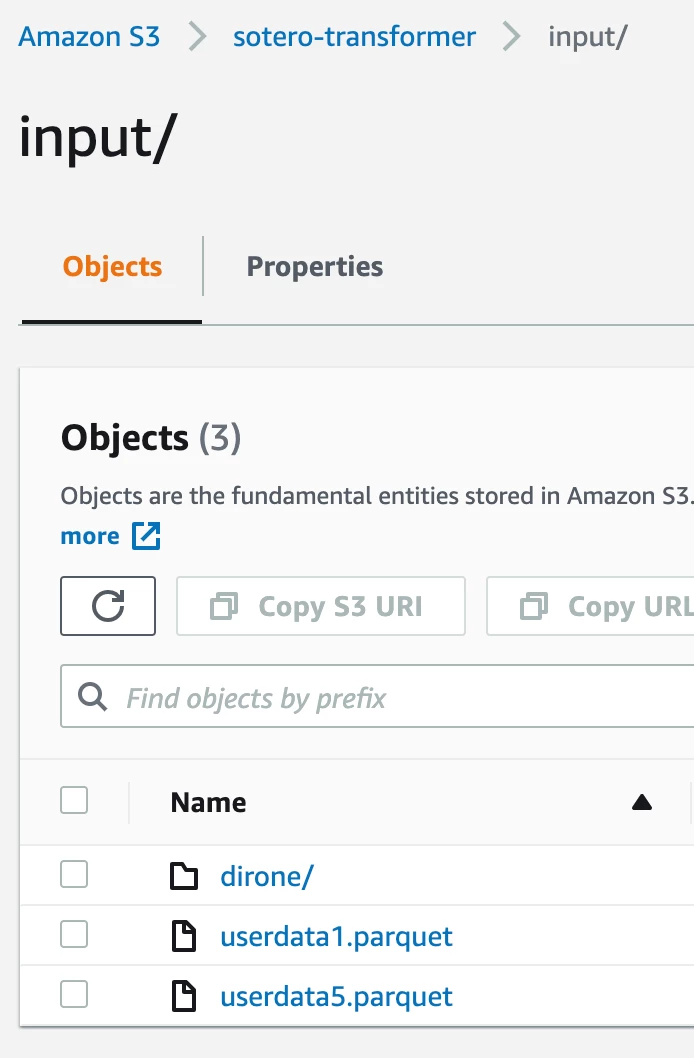
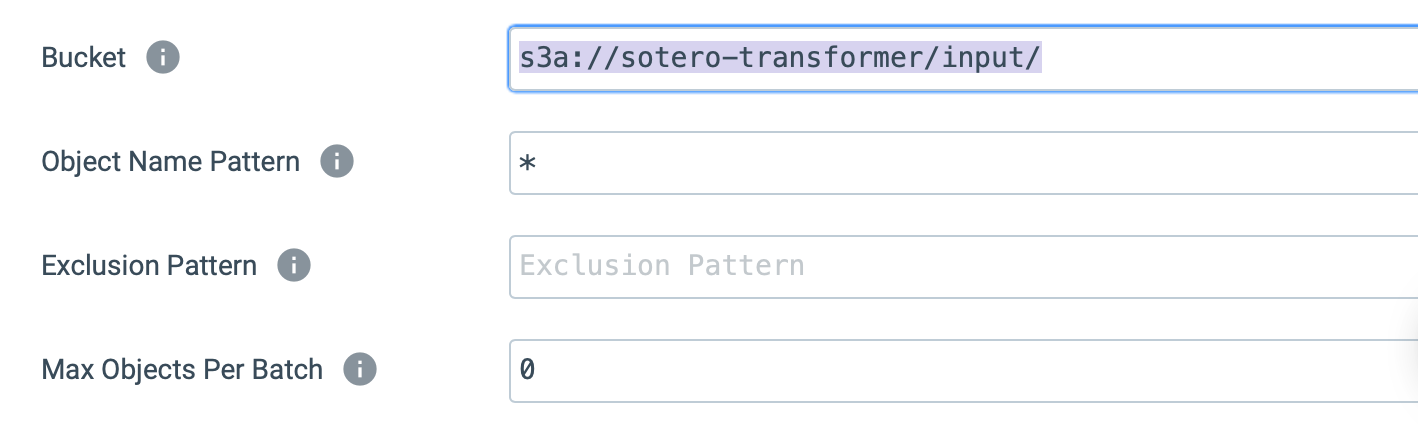
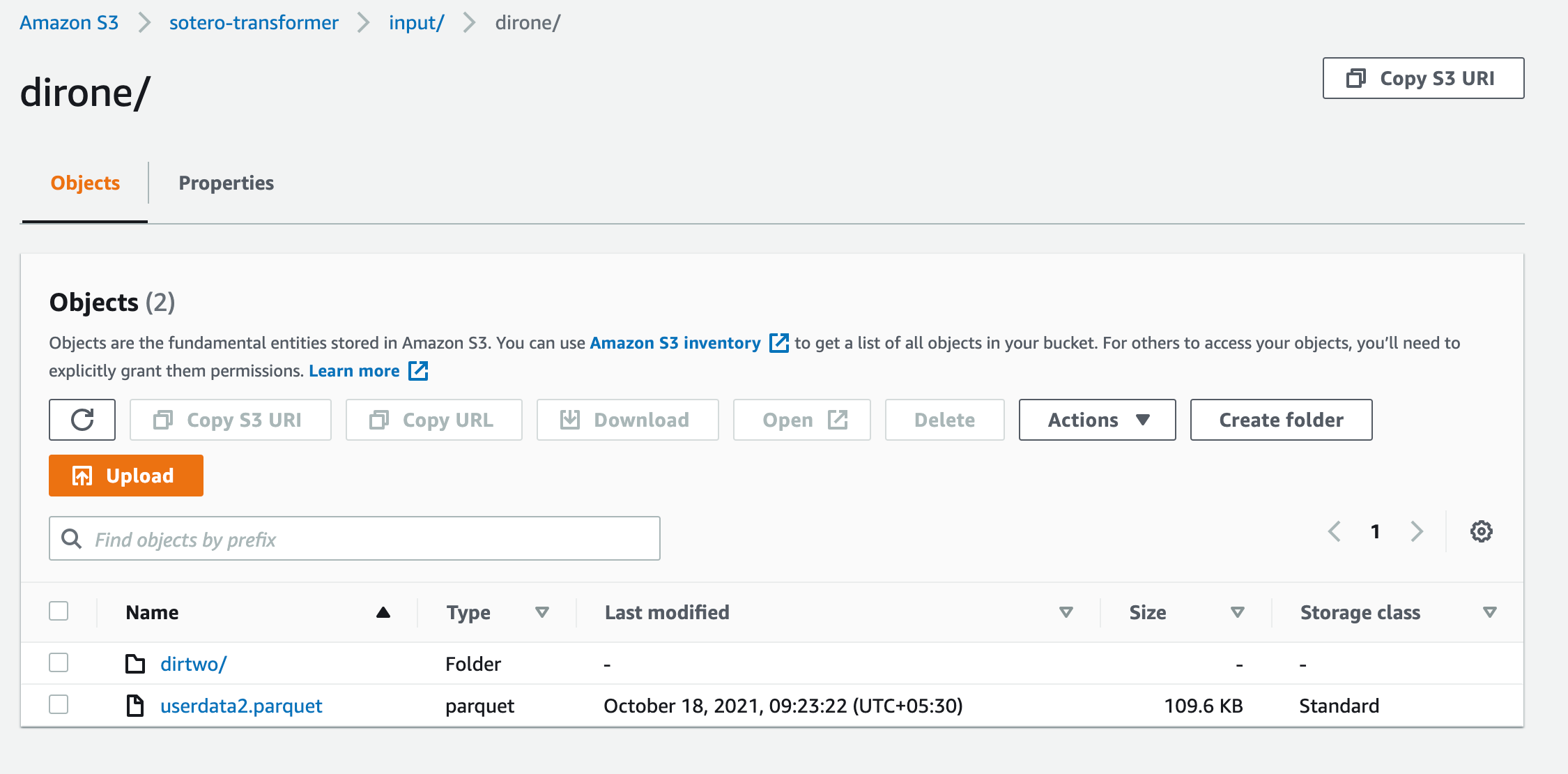
In the below image, for bucket “s3a://sotero-transformer/input/”, it reads the files userdata1.parquet and userdata2.parquet but doesn’t read the files under “dirone”.
What should be the configuration to read all the files under S3 bucket recursively?