
Hi experts,
I have one question and here is the scenario.
I am trying to connect from Mssql to AWS s3. I m going to do incremental load for 2 tables for example.
Everything will be done in 1 schema.
Table Name Pattern List - Table A , Table B
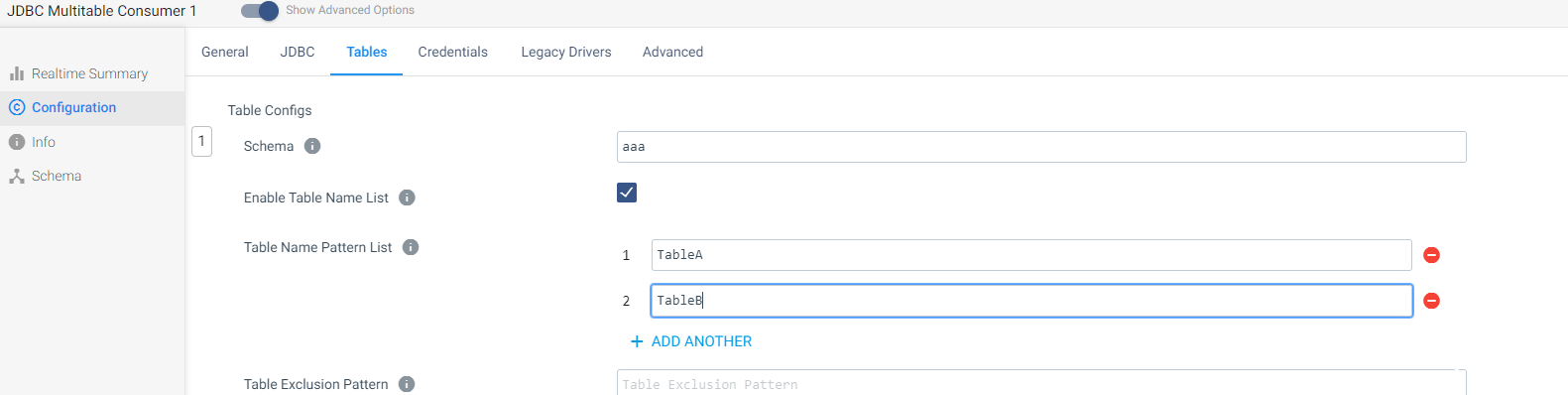
Table A
Offset column - LastUpdatedDate , Initial Offset Column - LastUpdatedDate , Value - “-2208988800000” which is “1900-01-01 00:00:00.000”
Table B
Offset column, Initial Offset Column, Value are all same with Table A.
How JDBC MultiTable handle the incremental load for two tables with same offset columns.
I try to update the rows in Table A, and I start the pipeline, it will get me the updated file and StreamSets will set the offset value itself. When I update or insert new records again, it will start reading data based on previous offset value and get the another updated file
However, when I try to update the rows in Table B, and I start the pipeline, I didn’t get anything.
What’s the problems here ?
My thought is like Table A , use first offset column. Table B , use second offset column. Both offset column for Table A and Table B are LastUpdatedDate. How to achieve it. Can it be done using JDBC MultiTable Consumer ?