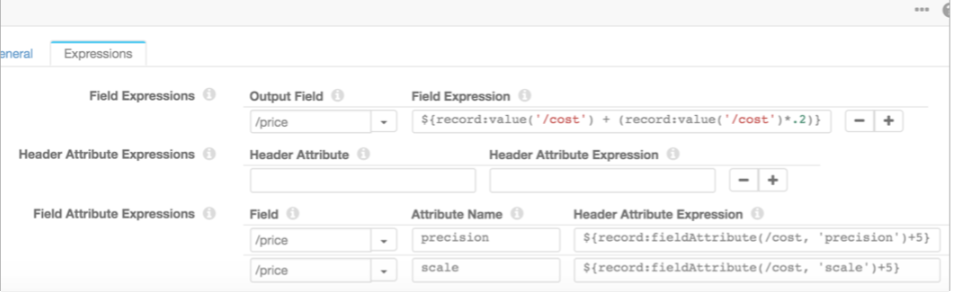
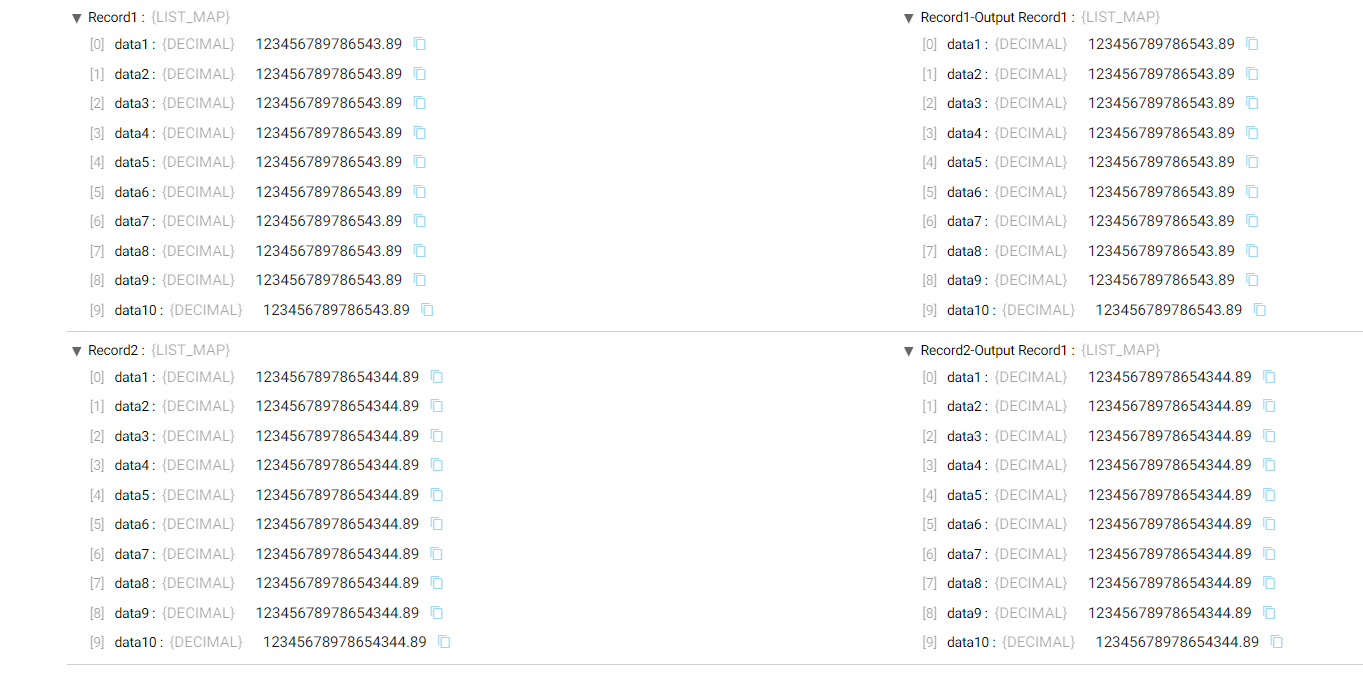
Precision and scale aren’t kept when copying numeric or decimal data from say SQL Server to Databricks via the JDBC Multitable Consumer origin. How can I maintain the original precision and scale in my pipeline? Will a Field type converter do it? If so, there’s an option for changing the scale, but not the precision.
Best answer by Bikram
View original