

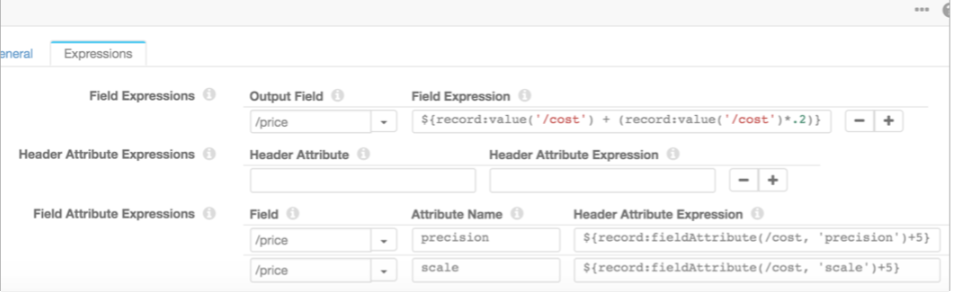
Precision and scale aren’t kept when copying numeric or decimal data from say SQL Server to Databricks via the JDBC Multitable Consumer origin. How can I maintain the original precision and scale in my pipeline? Will a Field type converter do it? If so, there’s an option for changing the scale, but not the precision.

Solved
JDBC Multitable Consumer to Databricks
- Opening Band
Best answer by Bikram
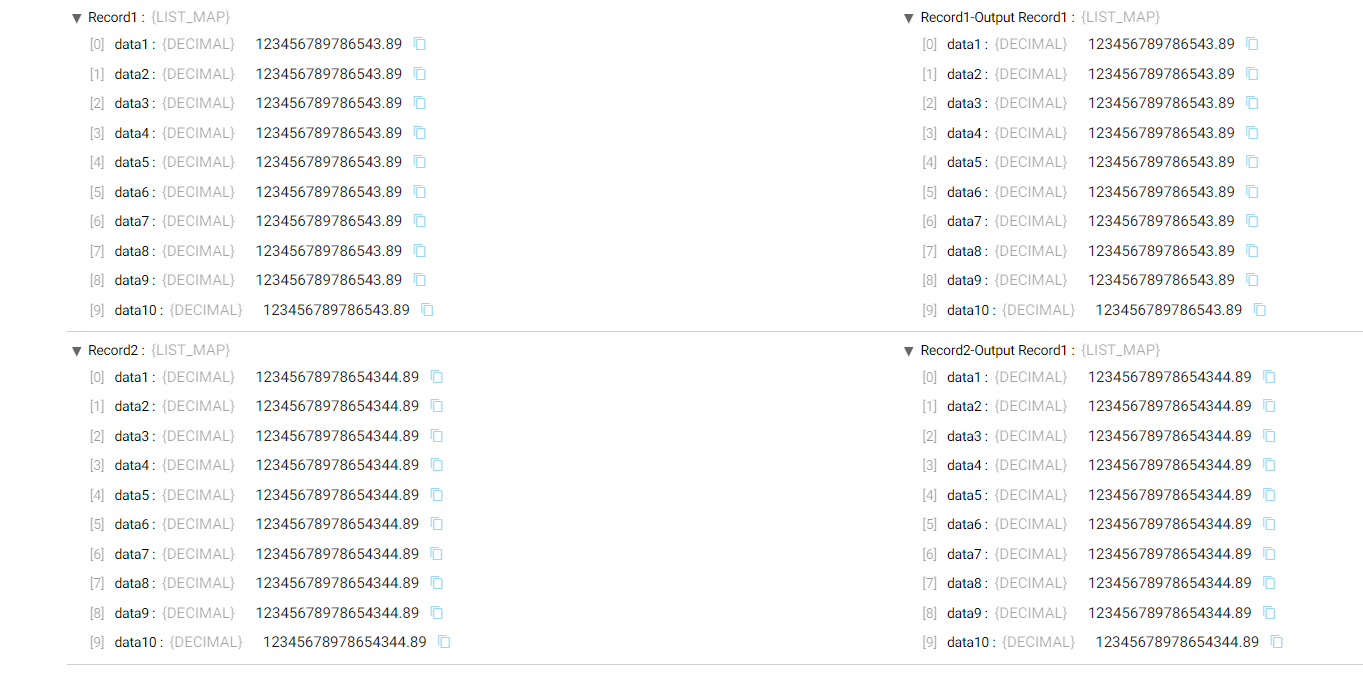
I just read the data from DB table having decimal values in it and the data is coming as expected. I am not seeing any changes in the data and not truncating any values while sending data to the destinations.
Below the sample input and output details for your reference. I believe in the destination end its truncating the values and taking the default values as (10,0).
I got the below details from the google as given below .
“
Both Spark and Hive have a default precision of 10 and scale of zero for Decimal type. Which means if you do not specify the scale, there will be no numbers after the decimal point.
“
Kindly check if data bricks having default value for decimal as (10,0) , then do the needful if possible.
Thanks & Regards
Bikram_



Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.