Also, we have not fixed number of “MAIN_*” tags, it is not fixed.
Page 1 / 1
Hi @yogesh0590
Have you tried using ‘Field Flattner’ processor and try to flatten ‘entire record’
You can also specify the separator when the flattening happens.
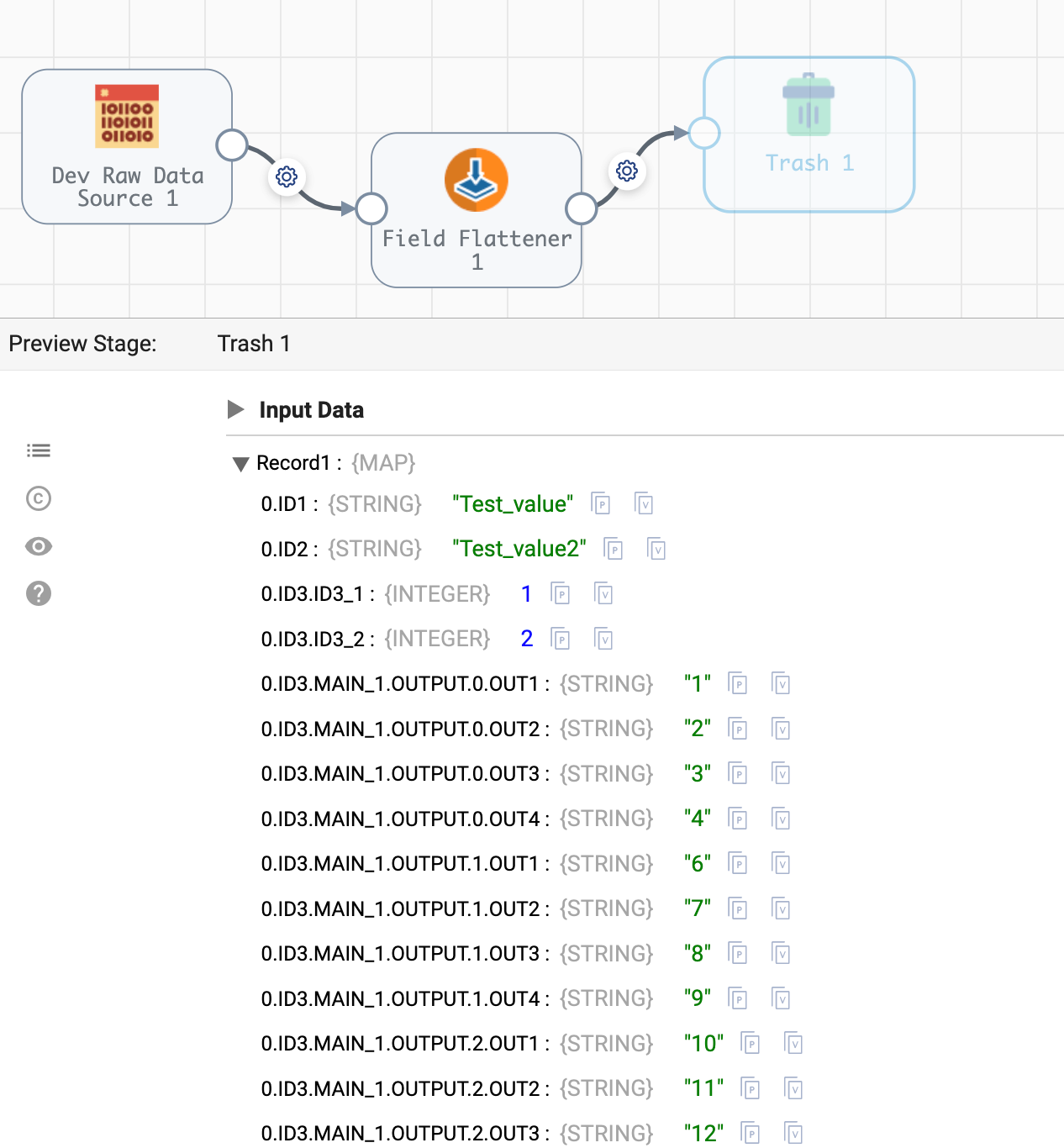
Thanks @saleempothiwala , I tried Field Flattener which is good if I have only one set of fields but in case of below structure how can I proceed. (Output should be two rows)
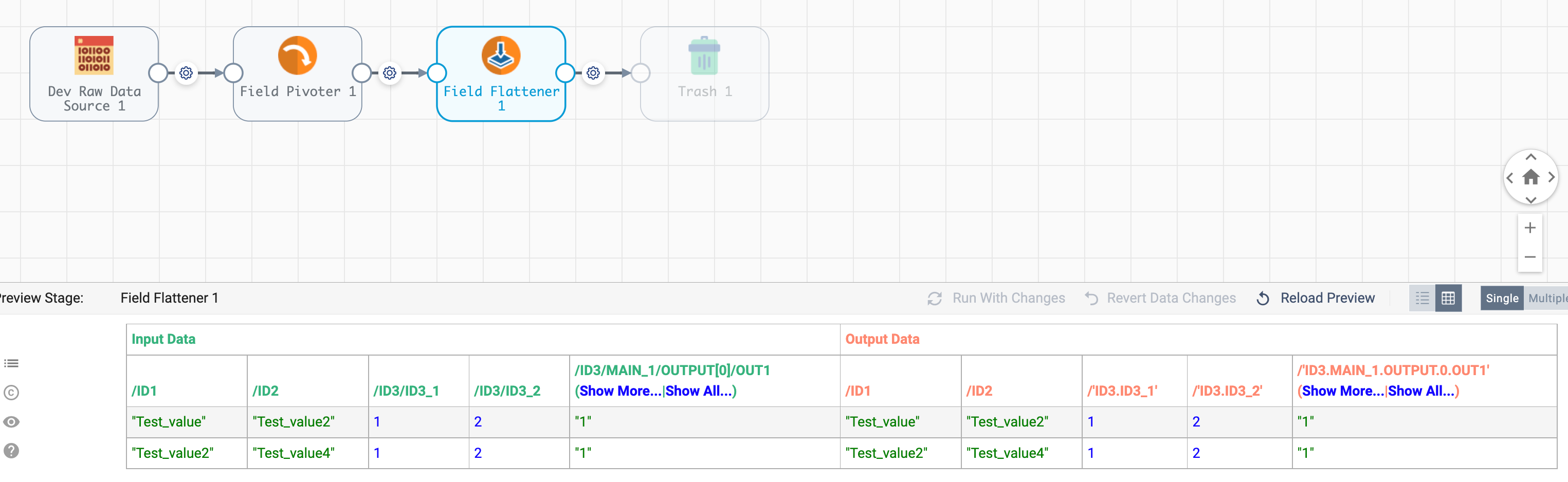
Just add a field pivoter that converts the list of records to separate records then your flattener will flatten two records.
Just add ‘/’ to the fields to pivot
@saleempothiwala : My bad , expected output is like this ,
ID1
ID2
ID3.ID3_1
ID3.ID3_2
ID3.MAIN_1.OUTPUT.OUT1
ID3.MAIN_1.OUTPUT.OUT2
ID3.MAIN_1.OUTPUT.OUT3
ID3.MAIN_1.OUTPUT.OUT4
ID3.MAIN_2.OUTPUT.OUT1
ID3.MAIN_2.OUTPUT.OUT2
ID3.MAIN_2.OUTPUT.OUT3
ID3.MAIN_2.OUTPUT.OUT4
Test_value
Test_value2
1
2
1
2
3
4
1
2
3
4
Test_value
Test_value2
1
2
6
7
8
9
6
7
8
9
Test_value
Test_value2
1
2
10
11
12
13
10
11
12
13
Test_value2
Test_value4
1
2
1
2
3
4
1
2
3
4
Test_value2
Test_value4
1
2
6
7
8
9
6
7
8
9
Test_value2
Test_value4
1
2
10
11
12
13
10
11
12
13
@yogesh0590
Tinker with the pivoter and use relevant level for pivoting to achieve the desired output.
@yogesh0590
Please find attached the pipeline , the result is as given above but due to multiple pivot processors in the pipeline the record count has been increased.
You can use scripting processors to adjust your data .
Please let me know if it helps .
Thanks & Regards
Bikram_
@Bikram@saleempothiwala
Thank You for your response but element “MAIN_*” are dynamic , it can be 1 or more than 1. So need to apply some stage so that it can handle it dynamically.
@yogesh0590
can you try to handle it in scripting processor.
@yogesh0590, as I said earlier, play around with the Pivoter to get the desired output. You might have to use * for wildcarding
@saleempothiwala
It seems in Pivoter we can’t process more than one field. And I tried using “*” as wild card but it is not supporting getting below error,
com.streamsets.pipeline.api.base.OnRecordErrorException: LIST_PIVOT_01 - Record 'mybucket/test.json::0' does not contain field '/ID3/*/OUTPUT'
@yogesh0590
you have to add a new Pivoter for each stage in the pipeline, like the pipeline Bikram sent as a zip file in thread.
And also you can take a look at the documentation for pivoter here