Hi
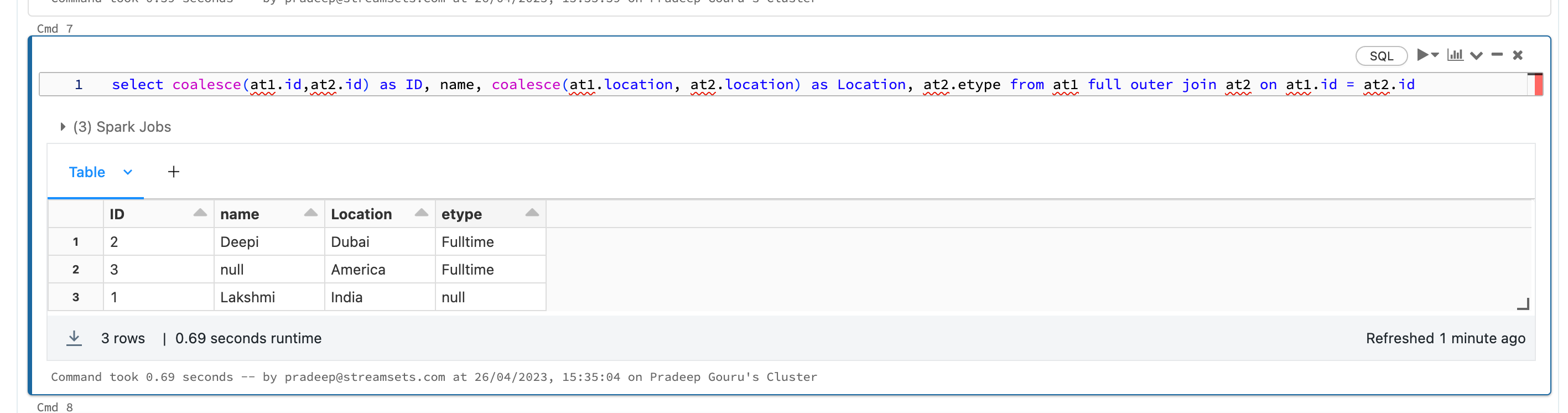
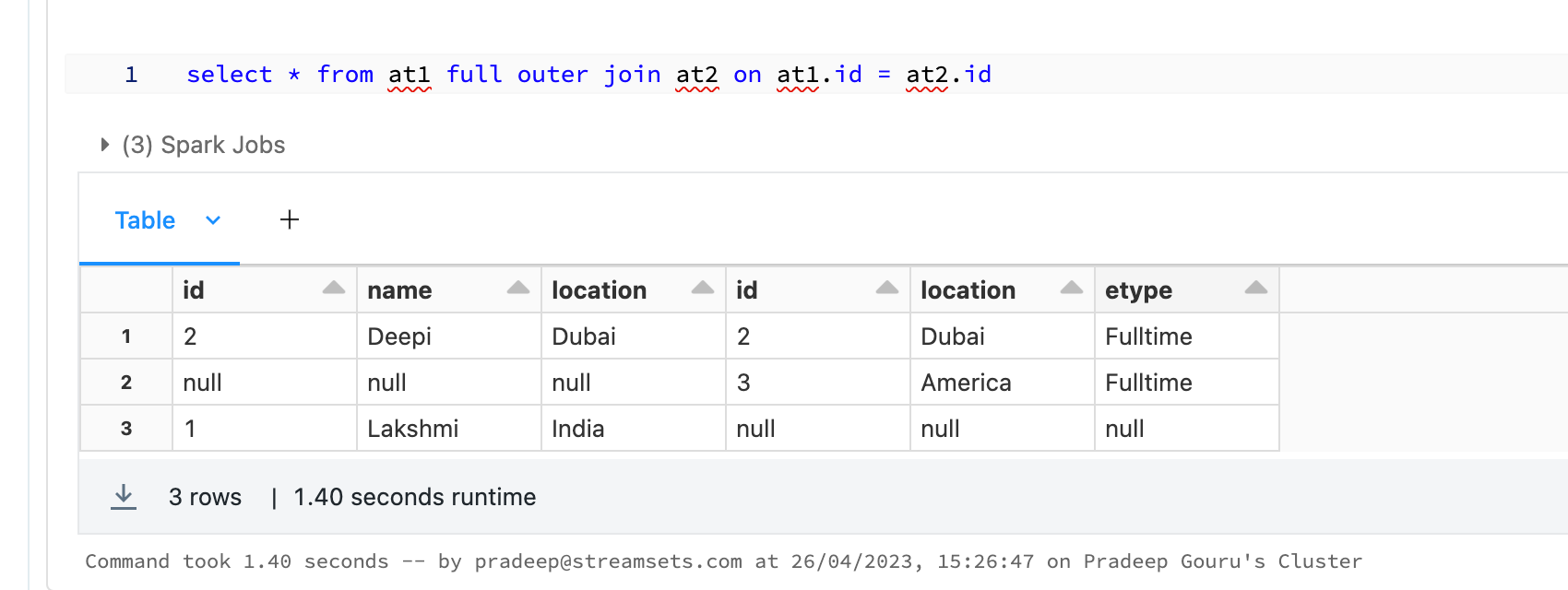
I have 2 tables
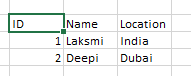
table one have 3 columns- ID, NAME,LOCATION.
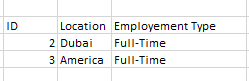
table two have 3 columns-ID,LOCATION, EMPLOYMENT TYPE
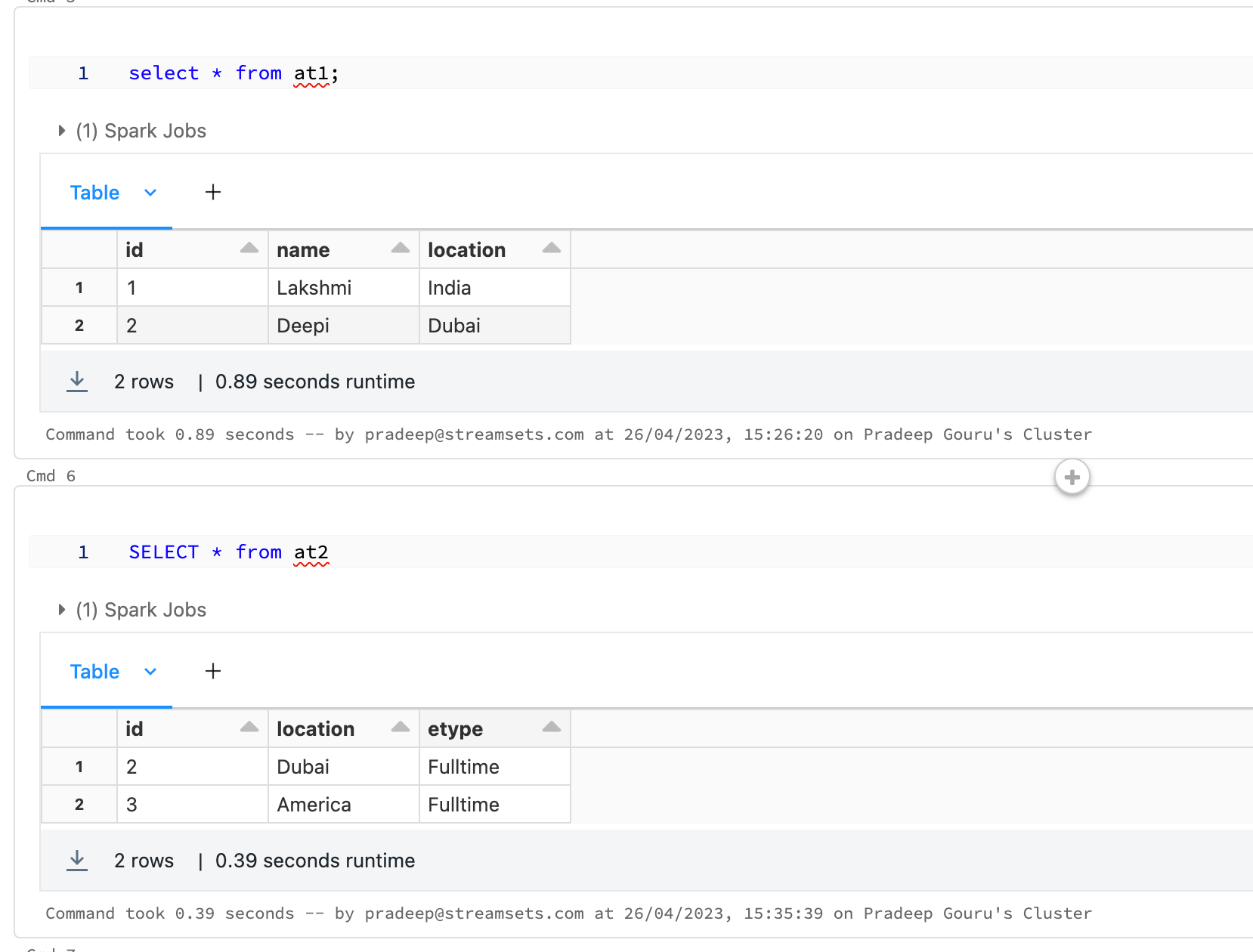
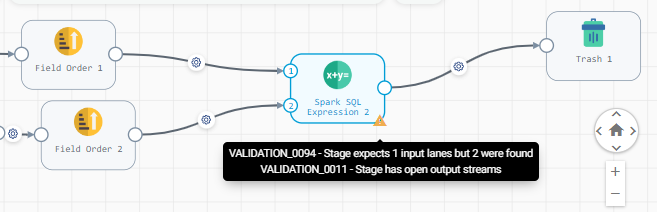
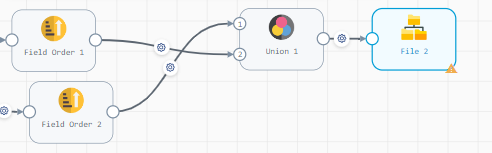
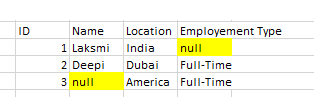
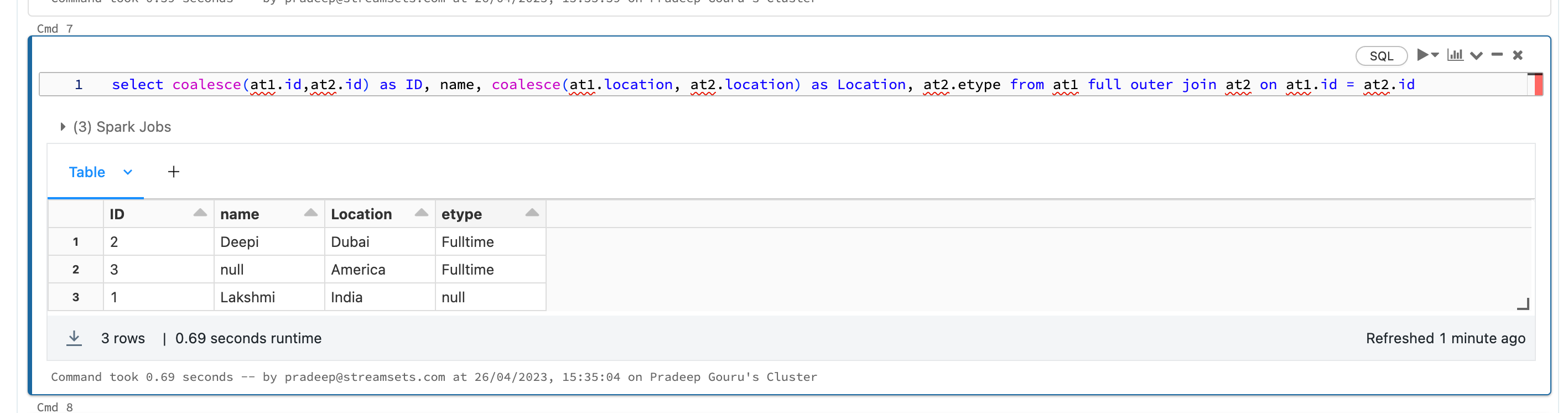
I need to merge the two data table as one after another not a join and expect output as combine both table in single table like
ID, NAME,LOCATION,EMPLOYMENT TYPE