Hi,
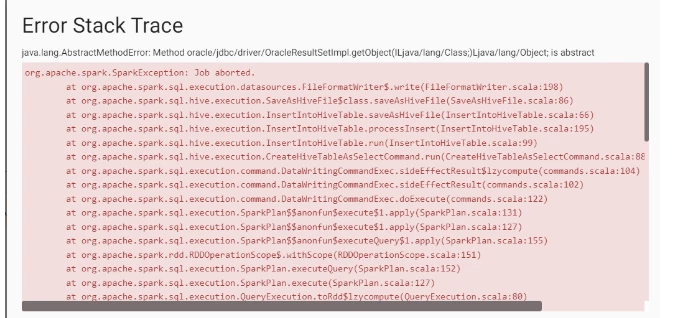
I am using Oracle JDBC Origin in Transformer and having an issue to save down the data frame into a Hive table. Below is the error screenshot of the same.
However, data is saved onto a table when i run pipeline in preview mode. In preview mode, i can see all the data types are of string, decimal and date timestamp.
I have tried reading only one string field and still can see same error message. Any help/suggesting would be appreciated.
Transformer version is 3.13.