I am trying to filter records by looking at a specific value from a table using jdbc lookup processor. My source has around 100k records and my jdbc lookup has only 1 record, but the pipeline is taking 2 minutes to write 1000 records to Hive. Overall the execution time is around 200 minutees for 100K records which is very bad. I request you to help me with this.

Page 1 / 1
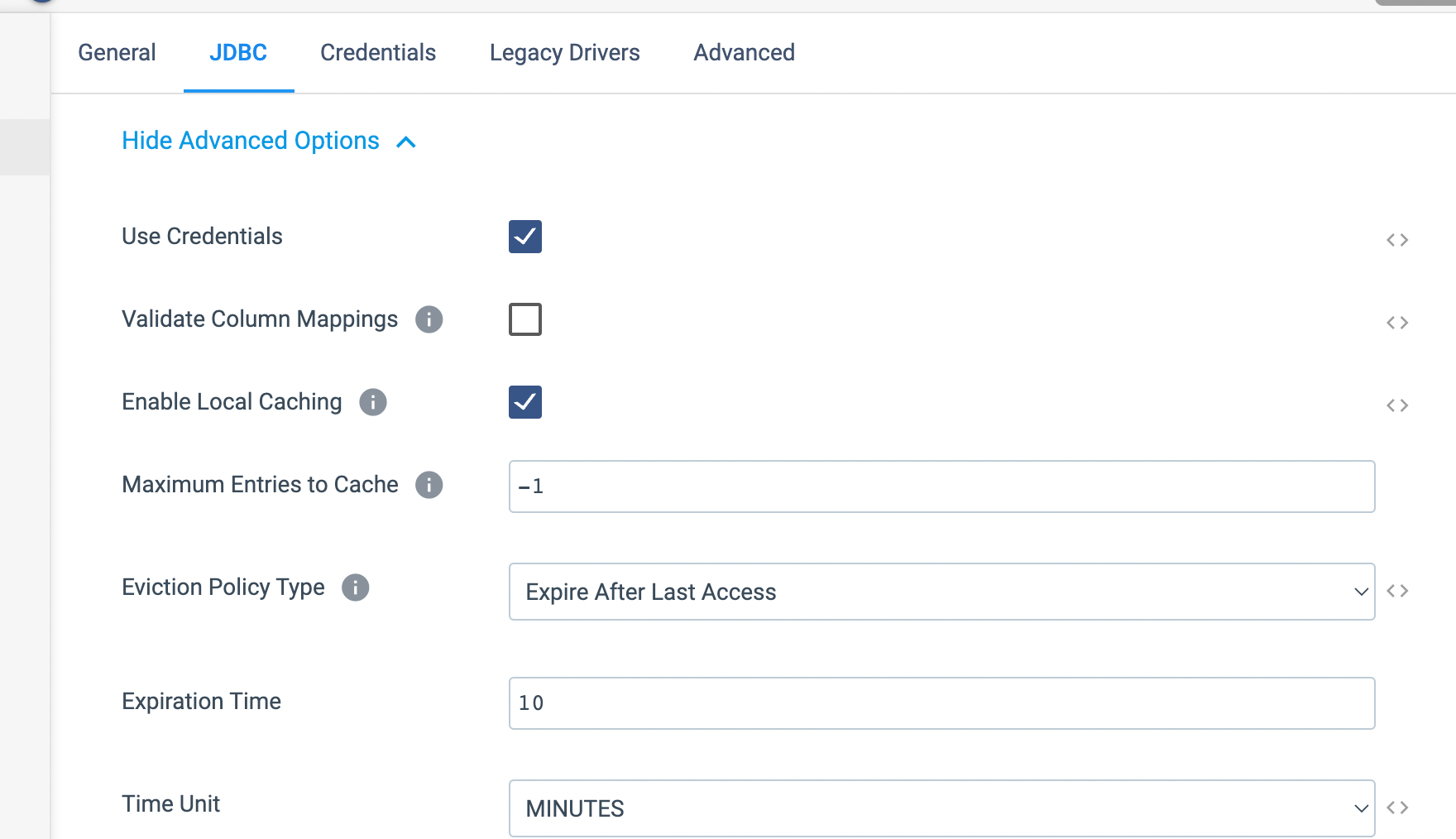
However, quick thing you can try by configuring the JDBC Lookup processor to locally cache the values returned from a database table. and you can also increase the number of threads that the JDBC Lookup processor uses to pre-populate the lookup cache.
checkout our document : https://docs.streamsets.com/portal/platform-datacollector/latest/datacollector/UserGuide/Processors/JDBCLookup.html#concept_jt5_kx2_px
Can you please enable the cache and try to execute the pipeline and let me know if it helps.
Reply
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.