Hi,
I am new to streamsets here, so please bear with my questions :) Here is my first one.
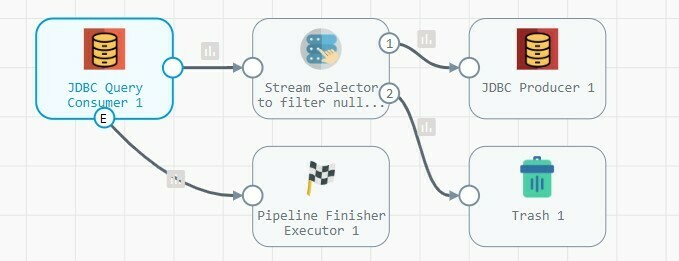
I created a simple pipeline to copy data from a employee table running sqlserver to employee table on postgresql. I used a JDBC Query consumer to pull records in incrementally using the offset value and a JDBC Producer stage to insert records.
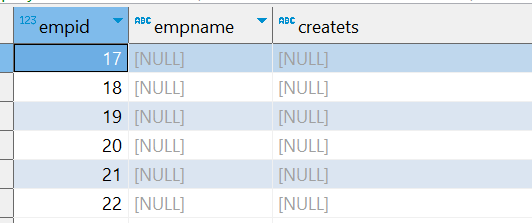
When I run the pipeline, it starts execution, select all records from sqlserver and inserts into postgres and then return a java.lang.NullPointerException. It goes into retry mode and continues to fail with same error on every retry attempt.
I tried adding more records in the table so that the next retry attempt would pull the new records based on the offset value, however, the pipeline is not pulling them.
I also tried filtering null records using stream selector, but it didnt work.
I also added Pipeline Finisher stage to end the pipeline when a “no more data” event is generated, but it doesnt seem to work as expected either. The pipeline continues to throw java.lang.NullPointerException on subsequent retires.
Kindly advise as to where I am going wrong here.
I have attached the log file(in case it helps)
Pipeline Config -
JDBC Query Consumer stage -
- JDBC connection to sqlserver
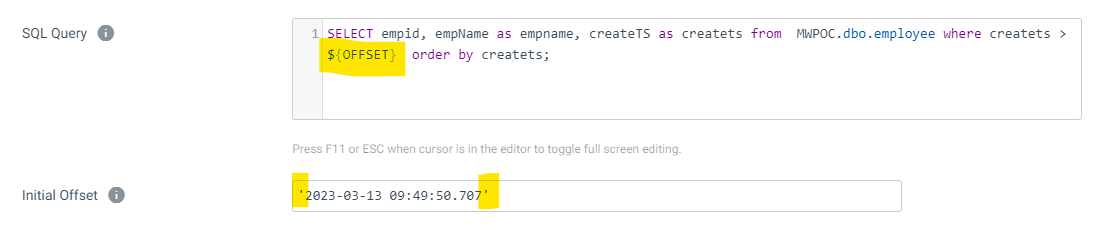
- SQL Query - SELECT empid, empName, createTS from MWPOC.dbo.employee where createTS > ${OFFSET} order by createTS;
- Initial Offset - '2023-03-13 09:49:50.707'
- Offset Column - createTS
- Mode - Incremental
Offset value in offset.json file in SDC after the pipeline stops is given below.
"offsets" : {
"$com.streamsets.datacollector.pollsource.offset$" : "2023-03-15 14:33:16.04"
},
JDBC Producer 1 stage -
- JDBC connection to postgresql
- schema - schema name of postgresql database
- table name - employee
Error Stack Trace: (attached)
Pipeline Flow: