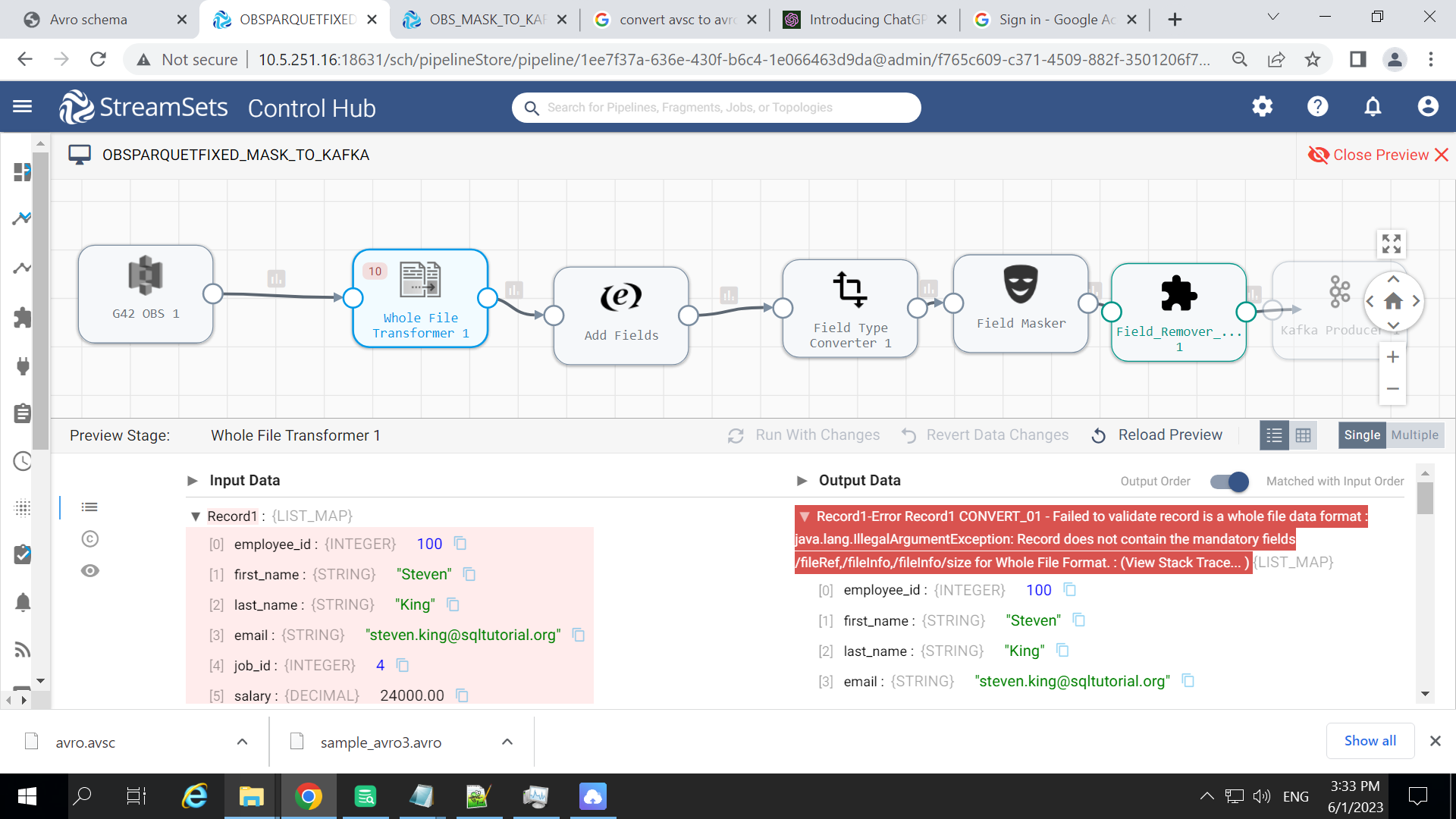
I am reading an avro file from a custom cloud similar to S3 and trying to conver it into parquet file using whole file evaluator but its giving an error
Record1-Error Record1 CONVERT_01 - Failed to validate record is a whole file data format : java.lang.IllegalArgumentException: Record does not contain the mandatory fields /fileRef,/fileInfo,/fileInfo/size for Whole File Format. : (View Stack Trace...