


Hi
I have the following orchestrating job:

The purpose of this pipeline is to first synchronize a list of tables via a full load between Oracle and Snowflake. After that, the CDC sync is started for each table passing the SCN that was read at the beginning. All jobs are executed in the background, so we can take advantage of running in parallel.
In the first step (SCN & Tables) I extract a list of tables and SCN and batch sizes. The output looks like this:
| TableName | SCN | BatchSize |
|---|---|---|
| Table1 | 123321 | 100 |
| Table2 | 123321 | 100 |
| Table3 | 123321 | 500 |
| ... | ... | ... |
Then this list is passed to step 3 (Start Bulk Load) and everything works as expected.
Step 3 starts per row a job. I have activated the option "Run In Background".
Here the expression of the parameters I’m passing in this step:
[{"tablename":"${record:value("/TABLENAME")}","batchsize":"${record:value("/BATCHSIZE")}"}
Then the same list is passed in step 5 (Start Oracle CDC) but only the first job of the table is created.
I also noticed this in job summary of step 3:
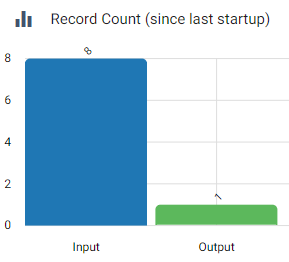
So I assume that after step 3, the collection of ${record:value("/TABLENAME")} is reduced to the first job that is completed in step 3.
Question: Can I somehow preserve the list from step 1 and restore it after step 3?


