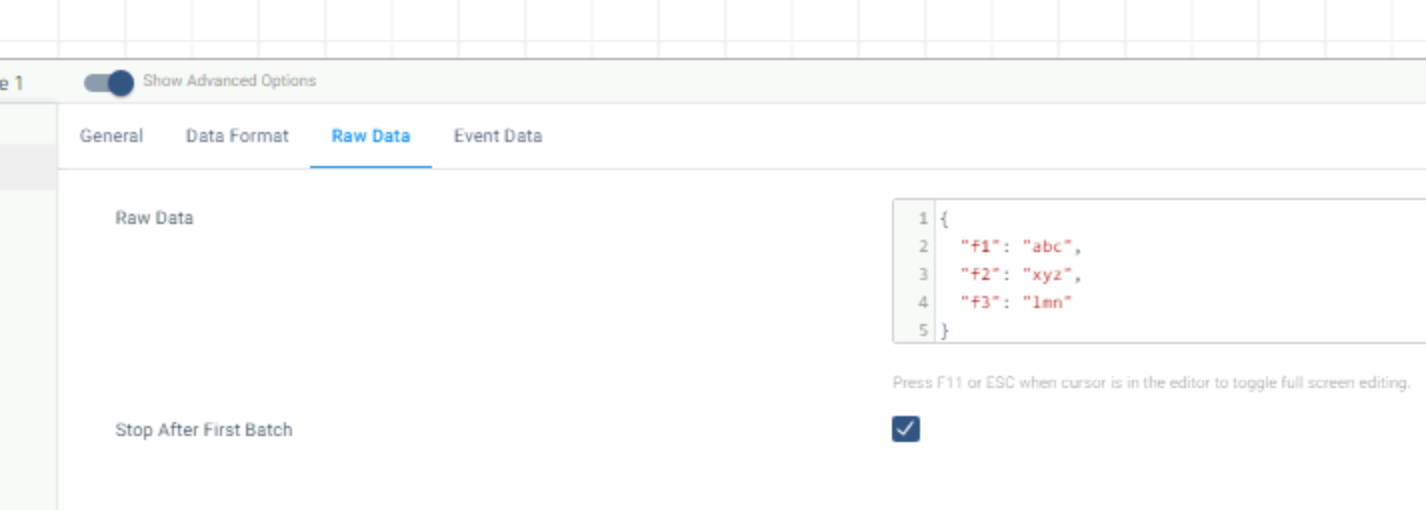
I have a pipeline that gathers records from an HTTP client. At one point in the pipeline I have a stream selector that filters out records that I don’t want and sends them to trash, while remaining records gets written to an S3 destination. At the end is a pipeline finisher executor.
The issue is when there are no remaining records after the stream selector, ie. the data contained no relevant records. In this case the pipeline job remains running indefinitely, and I have to stop it manually. How can I stop the pipeline when there are no records left after the stream selector?