
Hello everyone,
I’m currently having trouble building a data pipeline in streamsets, using MongoDB as my source input. The situation is as follows:
I have a pipeline that has MongoDB input as the source step. When I play the pipeline and hit the snapshot button, I'm able to see data coming just as I was expecting. Pay attention to the fact that every record has a single output and its own MongoDB _id (highlighted in red) :
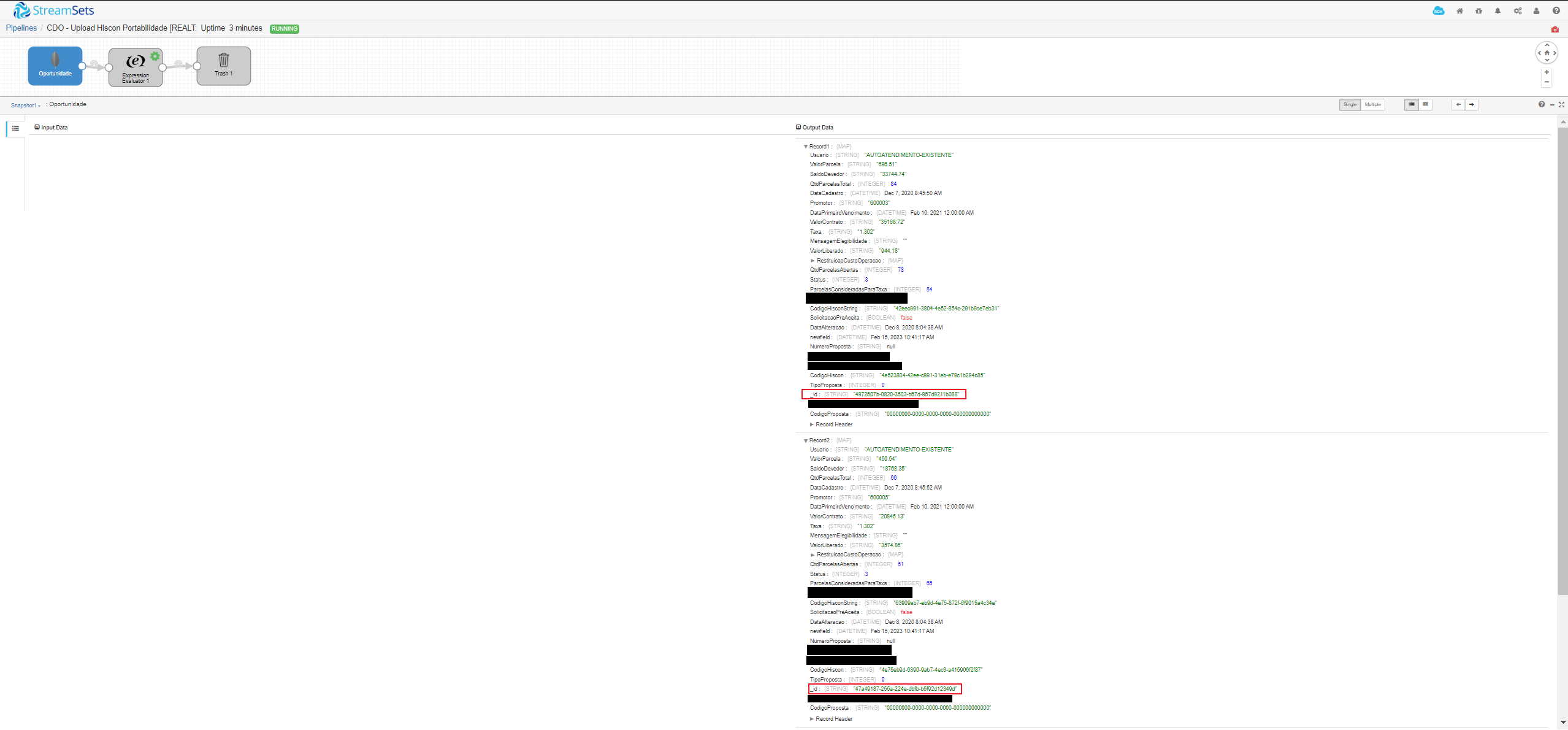
After the MongoDB input, I introduced a Expression Evaluator step just to work as an example, since any step I use will give me the same unexplainable results. The Expression Evaluator configuration is as follows:

After I pass these records through any kind of operation, e.g Expression Evaluator step, they seem to get some kind of cartesian product involving all the data from all records in each output.
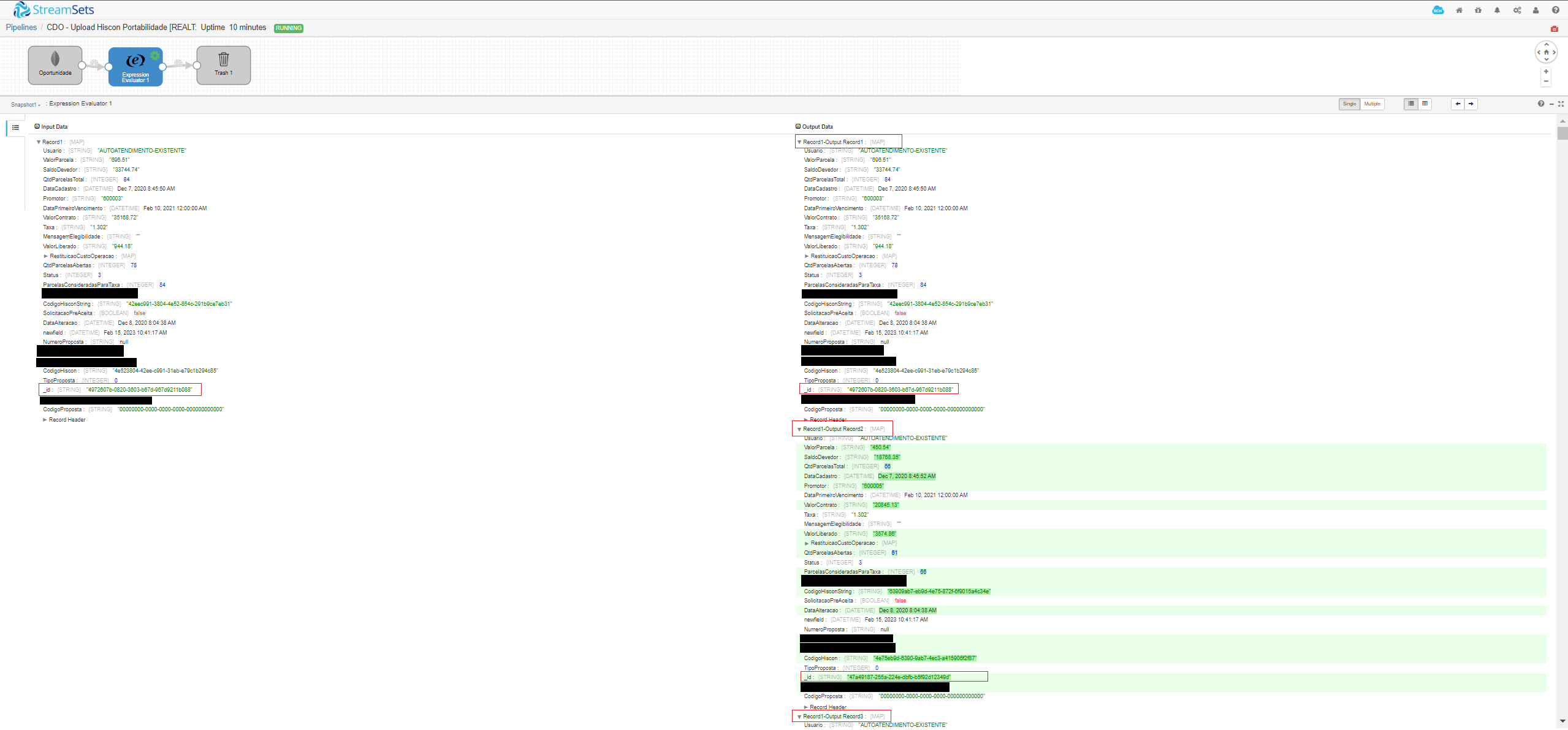
As you can see on the above print, now there are multiple output records for each input record that the source holds, and the _id of these outputs is changing according to the _id of the input records that were coming from the MongoDB step.
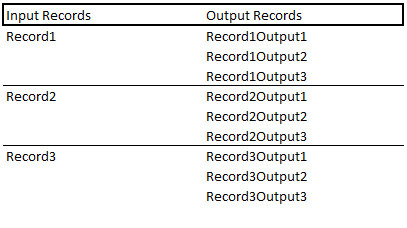
So if I have 10 records in de MongoDB input step, it will take the firts record and make 10 outputs for this record. After that, it will take the second record and make 10 outputs for the second record, and so on. It will end up with 100 output records.
It will do something similar to this:
I’m currently using the following setup:
StreamSets Data Collector 3.22.3-0046 running on a VM through Azure Marketplace
MongoDB Atlas 6.0