I am trying to use a Jython evaluator stage to remove the formatting and code encapsulation to only present the string content to be inserted in the destination stage (Snowflake). I have been searching online for ideas and guidance but have found very little, and most not helpful and/or pertinent to my quandary.
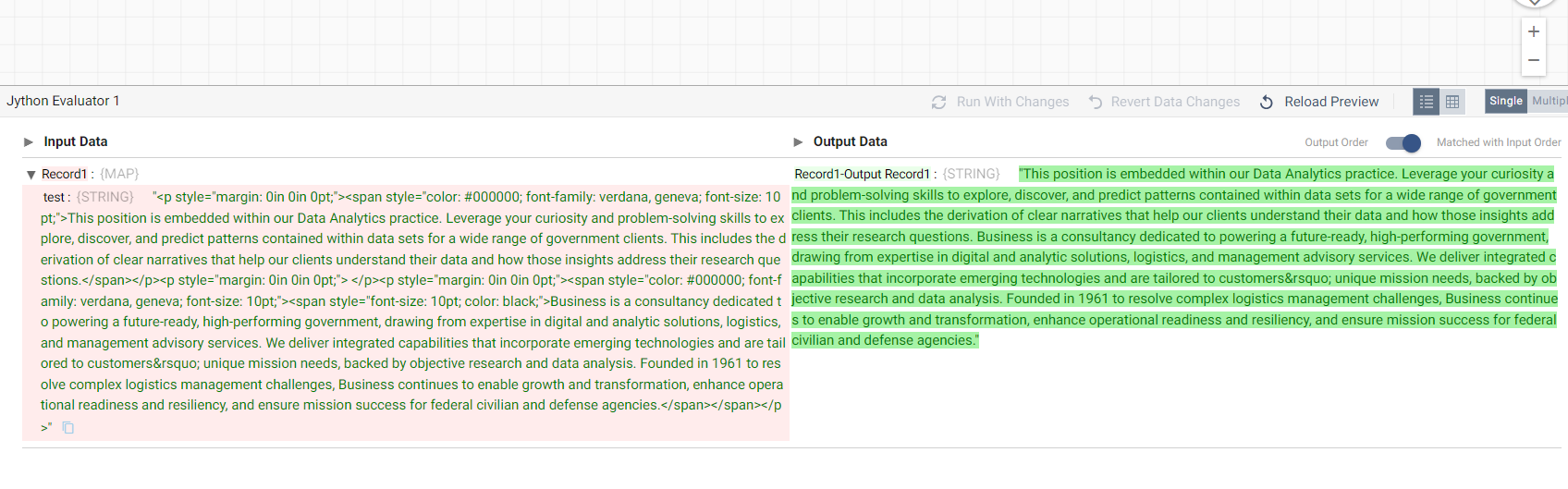
An example of the string incoming to the Jython stage:
<p style="margin: 0in 0in 0pt;"><span style="color: #000000; font-family: verdana, geneva; font-size: 10pt;">This position is embedded within our Data Analytics practice. Leverage your curiosity and problem-solving skills to explore, discover, and predict patterns contained within data sets for a wide range of government clients. This includes the derivation of clear narratives that help our clients understand their data and how those insights address their research questions.</span></p><p style="margin: 0in 0in 0pt;"> </p><p style="margin: 0in 0in 0pt;"><span style="color: #000000; font-family: verdana, geneva; font-size: 10pt;"><span style="font-size: 10pt; color: black;">Business is a consultancy dedicated to powering a future-ready, high-performing government, drawing from expertise in digital and analytic solutions, logistics, and management advisory services. We deliver integrated capabilities that incorporate emerging technologies and are tailored to customers’ unique mission needs, backed by objective research and data analysis. Founded in 1961 to resolve complex logistics management challenges, Business continues to enable growth and transformation, enhance operational readiness and resiliency, and ensure mission success for federal civilian and defense agencies.</span></span></p>
should be sent to the destination stage as this:
This position is embedded within our Data Analytics practice. Leverage your curiosity and problem-solving skills to explore, discover, and predict patterns contained within data sets for a wide range of government clients. This includes the derivation of clear narratives that help our clients understand their data and how those insights address their research questions. Business is a consultancy dedicated to powering a future-ready, high-performing government, drawing from expertise in digital and analytic solutions, logistics, and management advisory services. We deliver integrated capabilities that incorporate emerging technologies and are tailored to customers unique mission needs, backed by objective research and data analysis. Founded in 1961 to resolve complex logistics management challenges, Business continues to enable growth and transformation, enhance operational readiness and resiliency, and ensure mission success for federal civilian and defense agencies.
While I am an administrator I do have a bit of experience creating pipelines, but find myself tossed to the wolves as it were with full on developer duties until we replace a developer that has left the company. I am familiar (beginner - intermediate) with Python, but have zero experience with Java and thus started this effort by copying code from an existing pipeline and trying to modify that code to suit my needs.
The code I have (after exhausting every idea I can think of to get to this to work) is:
# Add additional module search paths:
try:
sdc.importLock()
import sys, unicodedata
finally:
sdc.importUnlock()
#Clean up Text
for record in sdc.records:
try:
if 'FULL_JOB_DESC' in record.value:
record.value['FULL_JOB_DESC'] = unicodedata.normalize('NFKD', record.value['FULL_JOB_DESC']).decode('UTF-8', 'ignore');
sdc.output.write(record)
except Exception as e:
sdc.error.write(record, str(e))
if 'JOB_QUALN' in record.value:
record.value['JOB_QUALN'] = unicodedata.normalize('NFKD', record.value['JOB_QUALN']).decode('UTF-8', 'ignore');
sdc.output.write(record)
except Exception as e:
sdc.error.write(record, str(e))
if'JOB_OVRVW' in record.value:
record.value['JOB_OVRVW'] = unicodedata.normalize('NFKD', record.value['JOB_OVRVW']).decode('UTF-8', 'ignore');
sdc.output.write(record)
except Exception as e:
sdc.error.write(record, str(e))
In case the formatting is off pasting it here I assure you that I have the tabs correct in StreamSets itself (that was one fo the first issues I resolved when starting this endeavor). I have tried changing the UTF-8 to HTML, CSS, XML but either there is no recognition of the supplied value or it understandably is not working because it does not apply to the string being passed into the stage. All three columns referenced in the script above are using the same formatting code, thus the single example I provided.
I appreciate any insight or assistance anyone may be able to offer me, and thank you in advance for your time expertise.