
Comparing with relational databases, at times we want to have some id field in our dataset which is always increasing(usually for every record insertion). In general, this is useful for indexing, ordering, to distinguish each record or in simple words to maintain integrity of the database. This might not be the case with distributed systems.
For Spark, data is mostly written to destination in partitions(that’s how we achieve parallelism). Since these partitions are written in parallel, we can not have consecutive id generation capability which is monotonically increasing. Spark has a function monotonically_increasing_id() which is helpful to generate increasing id at the partition level.
Below is what Spark documentation has to say about it.
A column that generates monotonically increasing 64-bit integers.
The generated ID is guaranteed to be monotonically increasing and unique, but not consecutive. The current implementation puts the partition ID in the upper 31 bits, and the record number within each partition in the lower 33 bits. The assumption is that the data frame has less than 1 billion partitions, and each partition has less than 8 billion records.
StreamSets Transformer has ‘Surrogate Key Generator’ processor which implements the monotonically_increasing_id() of Spark and also preserves the offset. Offset tracking of Surrogate Key Generator really helps in maintaining unique ids for all records at the level of partition.
Adding a sample pipeline here to demonstrate how Surrogate Key Generator works.
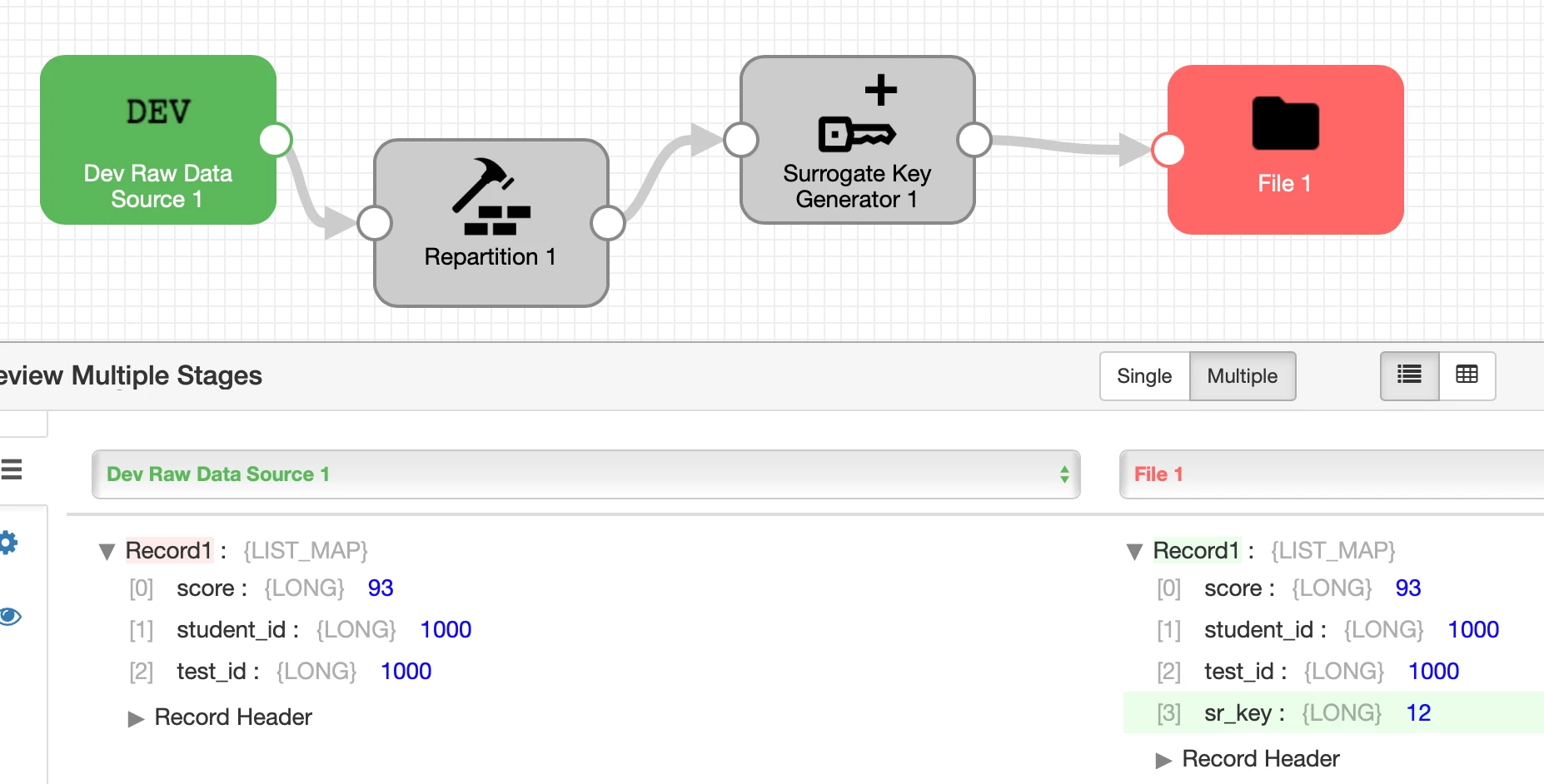
In the above pipeline, repartitioning is done based on student_id to divide data into 4 partitions and Surrogate Key Generator is emitting the monotonically increasing id as sr_key.
If we look at the head and tail of the 4 partitioned output files, can note sr_key has different range in each partition.
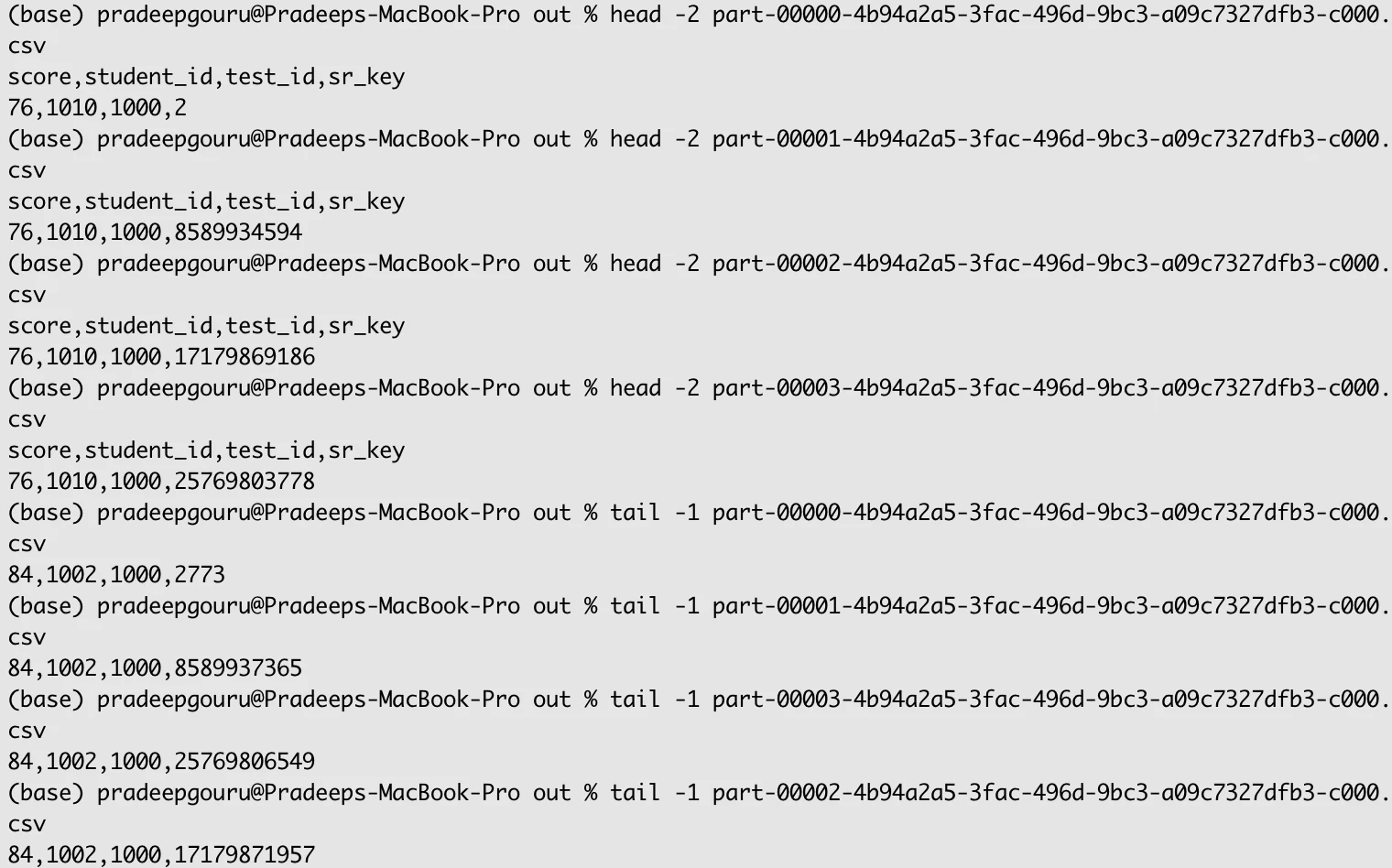
Only use of monotonically increasing id I can think of is when you want to sort the data within partition based on its insertion order. There might be other use cases where it will be helpful and do post here if you encounter or aware of any such cases.