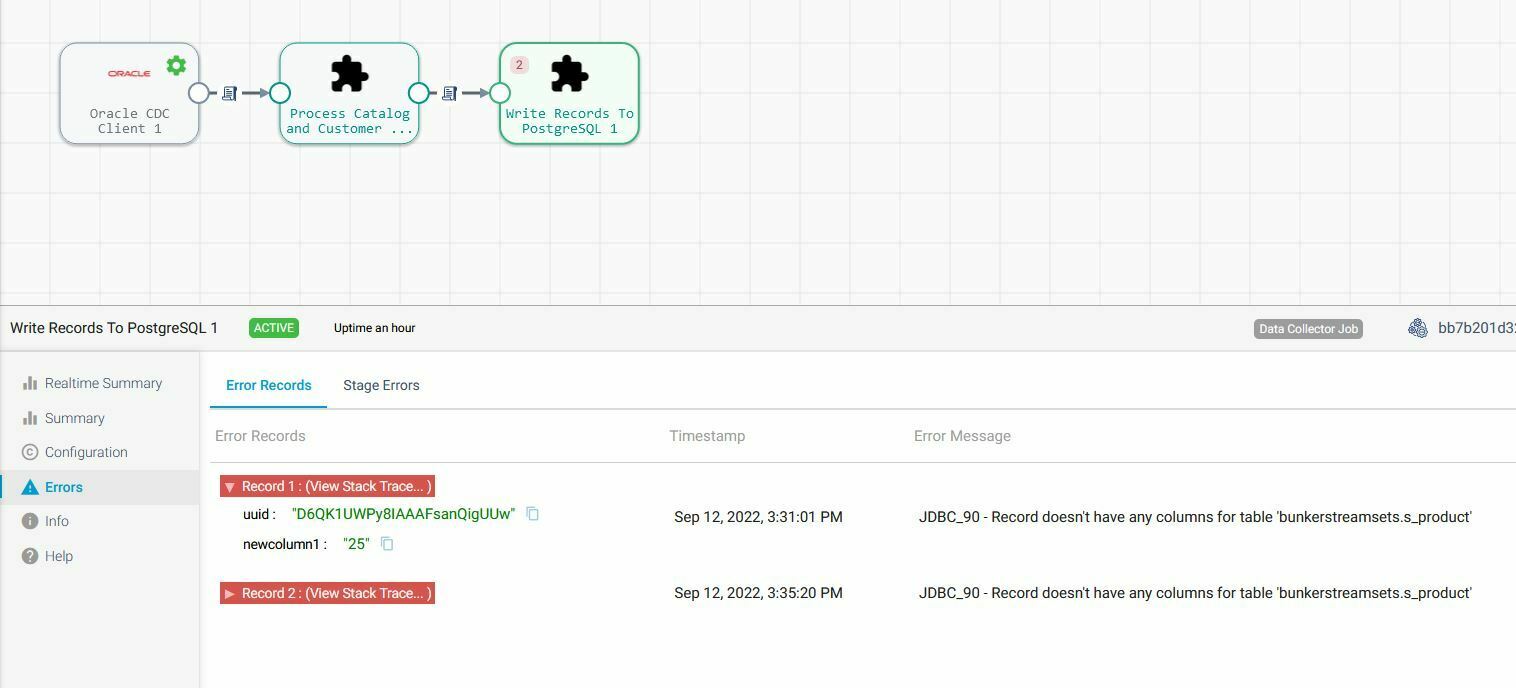
Hi, running the PostgreSQL Metadata processor and the JDBC Producer in a pipeline with the Oracle CDC client I run into the above error when adding a column to a table on the source side.
Checking the destination table I found that the Metadata processor altered the target table perfectly but it seems that the JDBC producer does not recognize the new field and assumes that the record, consisting of two columns, the primary key column and a value for the new added column does not carry any relevant data and issues the error.
I attach a screenshot with the pipeline and data.
May be someone has an idea what’s wrong? I checked the articles about data drift and cannot find any hint about what I may have configured wrongly.
Any help is greatly appreciated!
Here the stacktrace:
com.streamsets.pipeline.api.base.OnRecordErrorException: JDBC_90 - Record doesn't have any columns for table 'bunkerstreamsets.s_product'
at com.streamsets.pipeline.lib.jdbc.JdbcGenericRecordWriter.processQueue(JdbcGenericRecordWriter.java:199)
at com.streamsets.pipeline.lib.jdbc.JdbcGenericRecordWriter.write(JdbcGenericRecordWriter.java:164)
at com.streamsets.pipeline.lib.jdbc.JdbcGenericRecordWriter.writeBatch(JdbcGenericRecordWriter.java:111)
at com.streamsets.pipeline.lib.jdbc.JdbcUtil.write(JdbcUtil.java:1239)
at com.streamsets.pipeline.lib.jdbc.JdbcUtil.write(JdbcUtil.java:1161)
at com.streamsets.pipeline.stage.destination.jdbc.JdbcTarget.write(JdbcTarget.java:264)
at com.streamsets.pipeline.stage.destination.jdbc.JdbcTarget.write(JdbcTarget.java:253)
at com.streamsets.pipeline.api.base.configurablestage.DTarget.write(DTarget.java:34)
at com.streamsets.datacollector.runner.StageRuntime.lambda$execute$2(StageRuntime.java:291)
at com.streamsets.datacollector.runner.StageRuntime.execute(StageRuntime.java:232)
at com.streamsets.datacollector.runner.StageRuntime.execute(StageRuntime.java:299)
at com.streamsets.datacollector.runner.StagePipe.process(StagePipe.java:209)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.processPipe(ProductionPipelineRunner.java:859)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.lambda$executeRunner$3(ProductionPipelineRunner.java:903)
at com.streamsets.datacollector.runner.PipeRunner.acceptConsumer(PipeRunner.java:195)
at com.streamsets.datacollector.runner.PipeRunner.forEachInternal(PipeRunner.java:140)
at com.streamsets.datacollector.runner.PipeRunner.executeBatch(PipeRunner.java:120)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.executeRunner(ProductionPipelineRunner.java:902)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.runSourceLessBatch(ProductionPipelineRunner.java:880)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.runPollSource(ProductionPipelineRunner.java:602)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunner.run(ProductionPipelineRunner.java:388)
at com.streamsets.datacollector.runner.Pipeline.run(Pipeline.java:525)
at com.streamsets.datacollector.execution.runner.common.ProductionPipeline.run(ProductionPipeline.java:100)
at com.streamsets.datacollector.execution.runner.common.ProductionPipelineRunnable.run(ProductionPipelineRunnable.java:63)
at com.streamsets.datacollector.execution.runner.standalone.StandaloneRunner.startInternal(StandaloneRunner.java:758)
at com.streamsets.datacollector.execution.runner.standalone.StandaloneRunner.start(StandaloneRunner.java:751)
at com.streamsets.datacollector.execution.runner.common.AsyncRunner.lambda$start$3(AsyncRunner.java:150)
at com.streamsets.pipeline.lib.executor.SafeScheduledExecutorService$SafeCallable.lambda$call$0(SafeScheduledExecutorService.java:214)
at com.streamsets.datacollector.security.GroupsInScope.execute(GroupsInScope.java:44)
at com.streamsets.datacollector.security.GroupsInScope.execute(GroupsInScope.java:25)
at com.streamsets.pipeline.lib.executor.SafeScheduledExecutorService$SafeCallable.call(SafeScheduledExecutorService.java:210)
at com.streamsets.pipeline.lib.executor.SafeScheduledExecutorService$SafeCallable.lambda$call$0(SafeScheduledExecutorService.java:214)
at com.streamsets.datacollector.security.GroupsInScope.execute(GroupsInScope.java:44)
at com.streamsets.datacollector.security.GroupsInScope.execute(GroupsInScope.java:25)
at com.streamsets.pipeline.lib.executor.SafeScheduledExecutorService$SafeCallable.call(SafeScheduledExecutorService.java:210)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at com.streamsets.datacollector.metrics.MetricSafeScheduledExecutorService$MetricsTask.run(MetricSafeScheduledExecutorService.java:88)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
And the screenshot: