



Dear Community Users,
I’ve been using StreamSets OSS for few months now and trying to come up with different ways how I can use it in my Organization for various ETL and Reverse ETL use cases. During this journey - we have come up with many small/medium exercises and I beleive sharing them with community may help others to save some time. This is the very first item in my micro-blogging series where I’m sharing how we are converting a CSV record into a JSON.
Problem Stement:
Convert records coming in a CSV file to JSON before publishing them to a target destination.
Input Data Format:
NAME|AGE|DEPARTMENT|ADDRESS
"John"|"23"|"HR"|"31, 2nd Cross, 4th Street, Wilson-543234"Output Data Format:
{
"data": {
"NAME": "John",
"AGE": "23",
"DEPARTMENT": "HR",
"ADDRESS": "31, 2nd Cross, 4th Street, Wilson-543234"
}
}
- Origin: A DEV Data Genrator that has records as below. We have set the data format to “delimiter” with custom delimiter set to pipe (|).
NAME|AGE|DEPARTMENT|ADDRESS
"John"|"23"|"HR"|"31, 2nd Cross, 4th Street, Wilson-543234"
"Amanda"|"26"|"HR"|"24, 1st Cross, Wilson Garden-543234"- Jython Evaluator: This is where we are wrapping every record inside a “/data” list map.
for record in records:
try:
# Save existing value, create new map, put saved value in the map
tmp = record.value
record.value = sdcFunctions.createMap(True)
record.value['data'] = tmp
# Write record to processor output
output.write(record)
except Exception as e:
# Send record to error
error.write(record, str(e))- JSON Generator: Serializing the root element and storing them under “/data” filed.

As you can see below - a preview of the pipeline does demonstrate that the input CSV is now converted into a JSON.
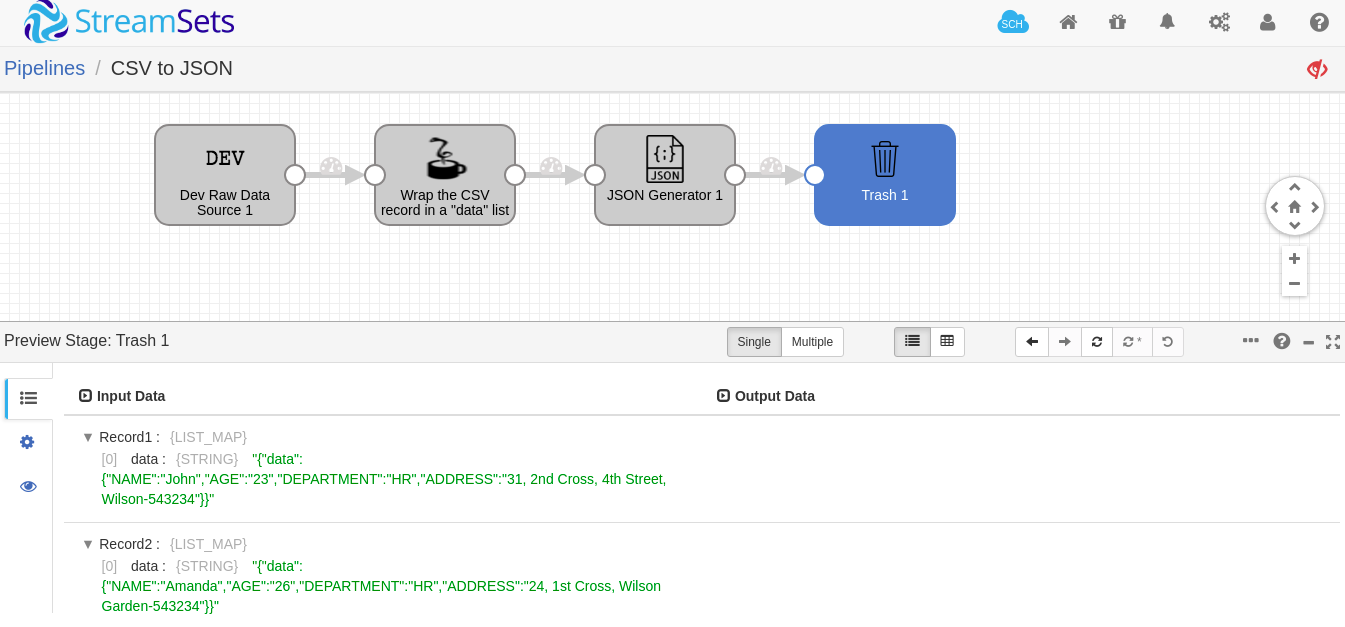
Conclusion:
This is simple but worth to note that sometime these little tricks saves a lot of time for developers. Same problem statement can be addressed using StreamSets existing stage processor (without using external script evaluator) or probably converting Jython into Groovy as Groovy is more performant that Jython. If you want to contribute using these additional tricks for the same problem statement, please do comment and contribute to the community.

