
In this article, we'll configure the Azure Synapse Dedicated SQL pool and insert some records from Mysql.
Platform:
- Streamsets Data Collector version 5.0
- MySql version 8.0.28.
Pre-requisite:
- Mysql connector driver for JDBC query consumer stage.
- Install Azure Synapse Enterprise Library 1.1.0 from PackageManager to enableAzure Synapse SQL destination.
Configuration:
Step1: When you create the workspace in Azure Synapse, you will be creating a storage account and workspace however it does not create a SQL pool. You would need to create the SQL pool from:
Azure Analytics » Click on Workspace web URL » Manage and then click on “new”. This will create the Azure SQL pool.
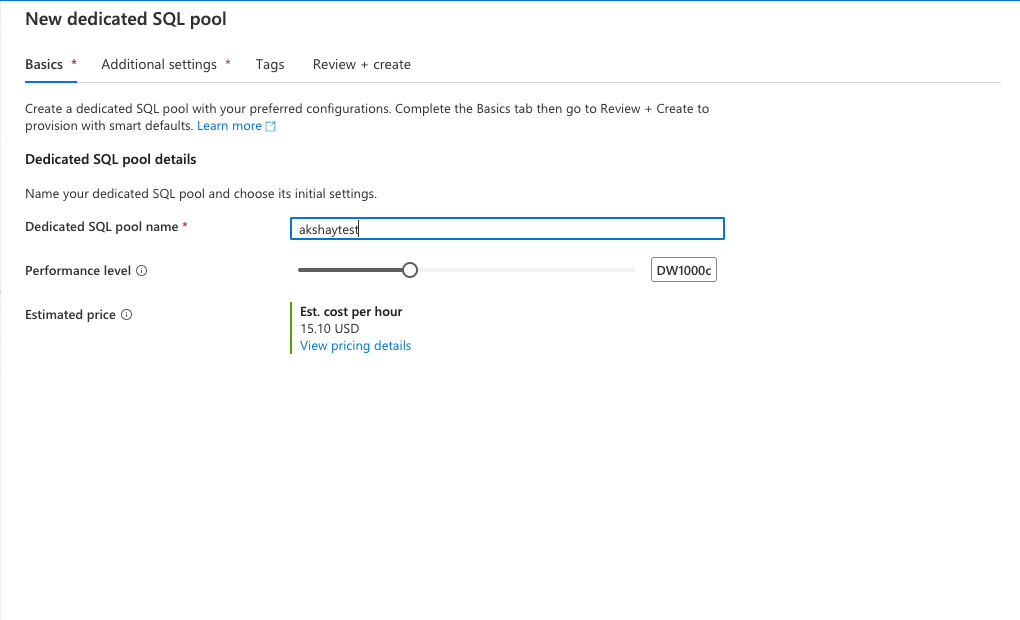
Once done, you will be able to see the SQL pool in the overview tab. “akshaytest” is the new sql pool here.

Step2: Develop the pipeline with JDBC Query Consumer origin and Azure Synapse SQL destination.
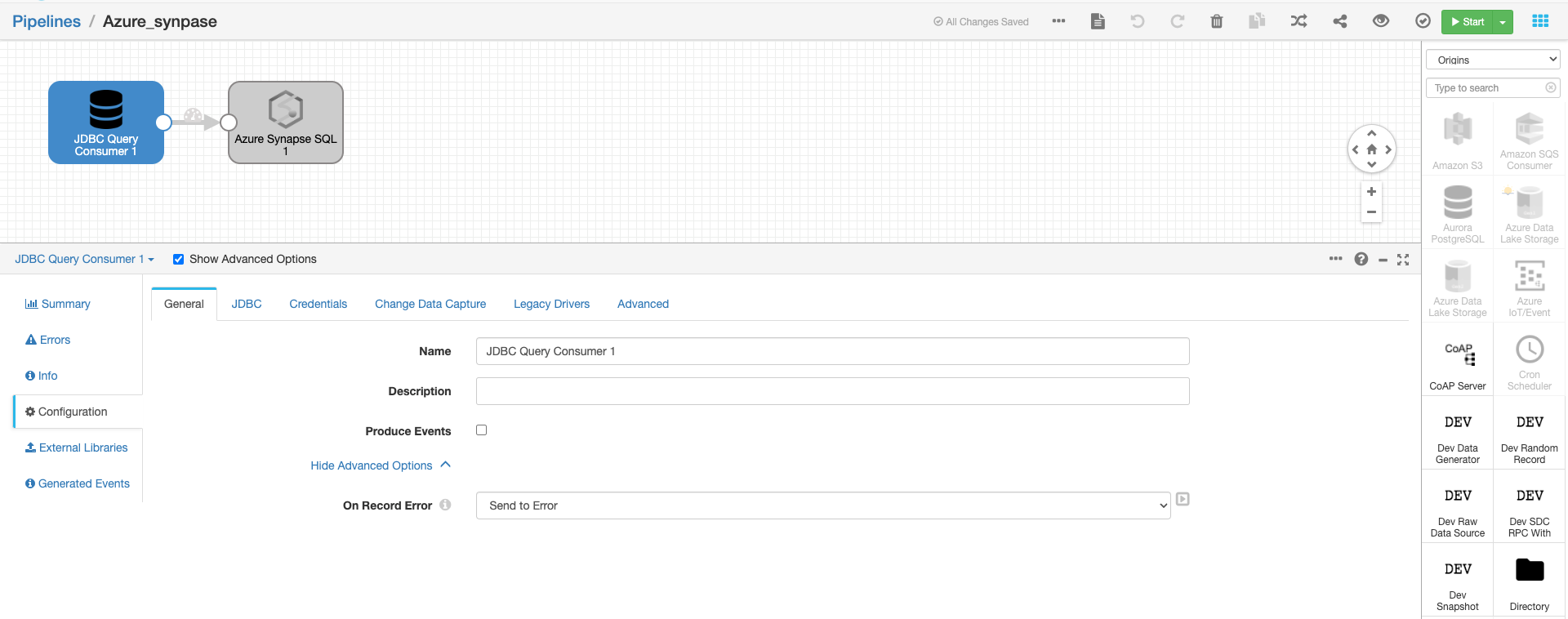
In the JDBC consumer, we would be reading all the data from the “Azure” mysql database which is hosted on the local machine.
These are the records we would be reading:
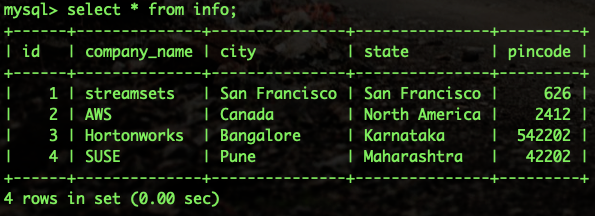
Step3: Validate the pipeline to ensure all the configuration are correct and there are validation errors.
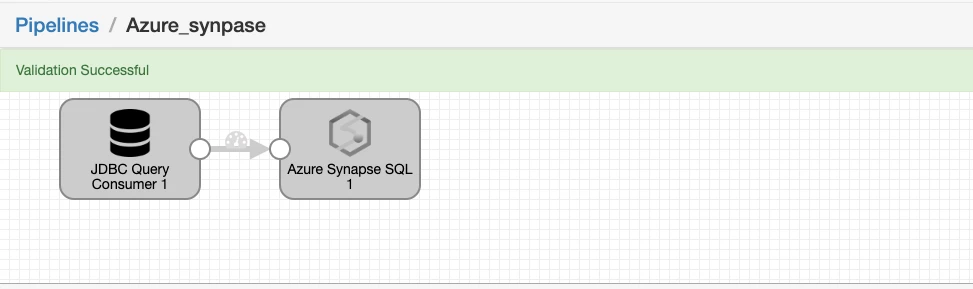
Run the pipeline when you see validation successful. In the summary section, I can see 4 records were process successfully.
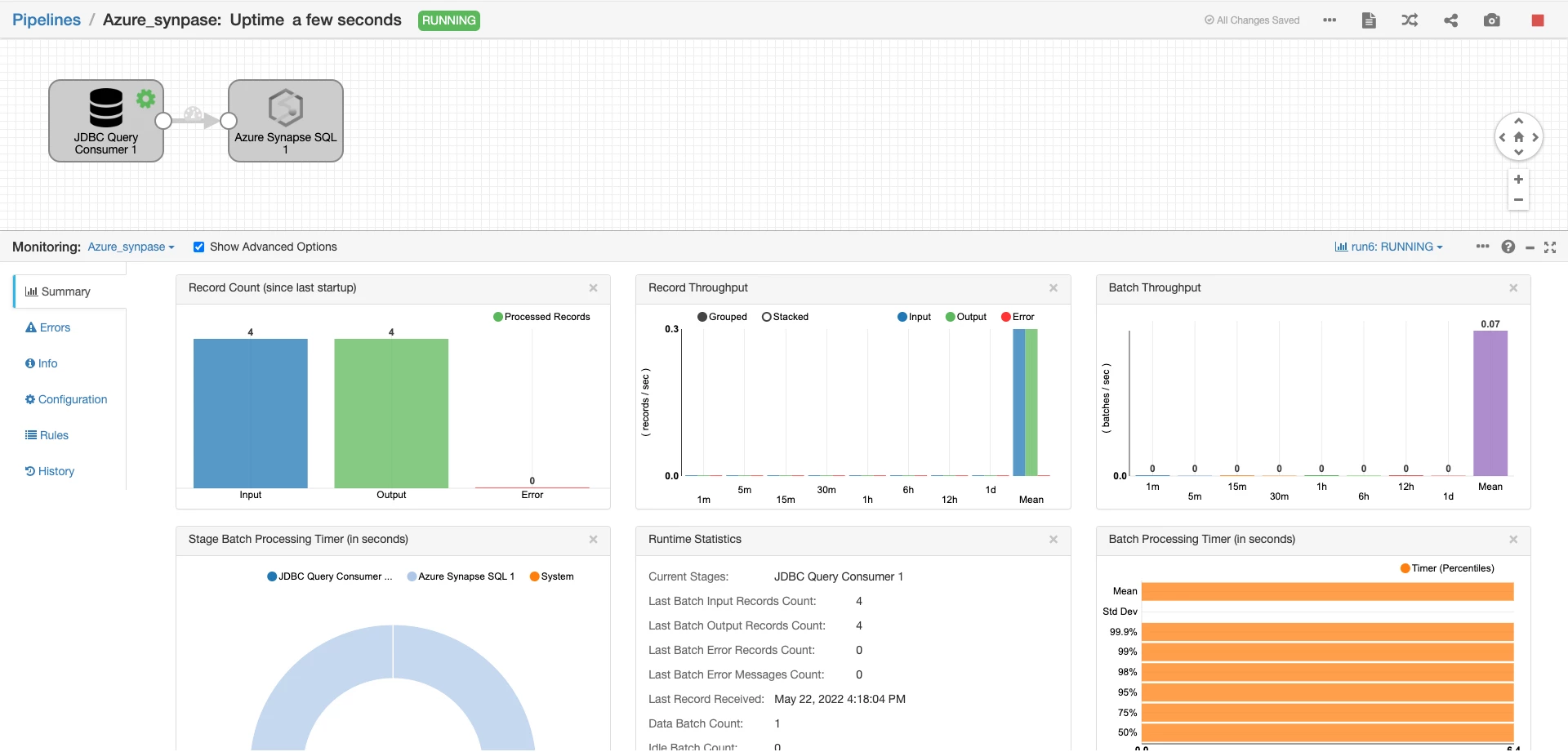
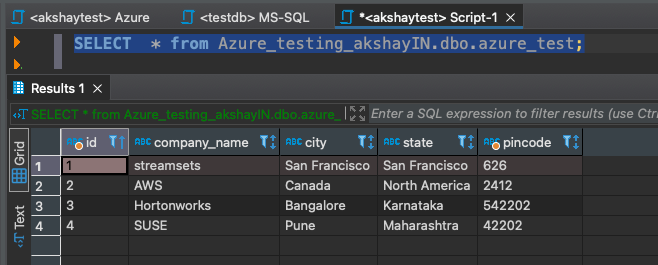
To verify this, I’ve configure the DBviewer tool to access the Azure SQL instance to check the records available in the database “azure_test”.
You can use any origin like Dev Data Generator/CDC tracking and process the data to the Azure synapse sql pool.
Note: You can always refer to the documentation section to get more details about the stage configurations. I’m attaching the pipeline to the article for reference.
Azure Synapse SQL:-
JDBC Query Consumer:-