Hi, I am new to Streamsets, started using it today.
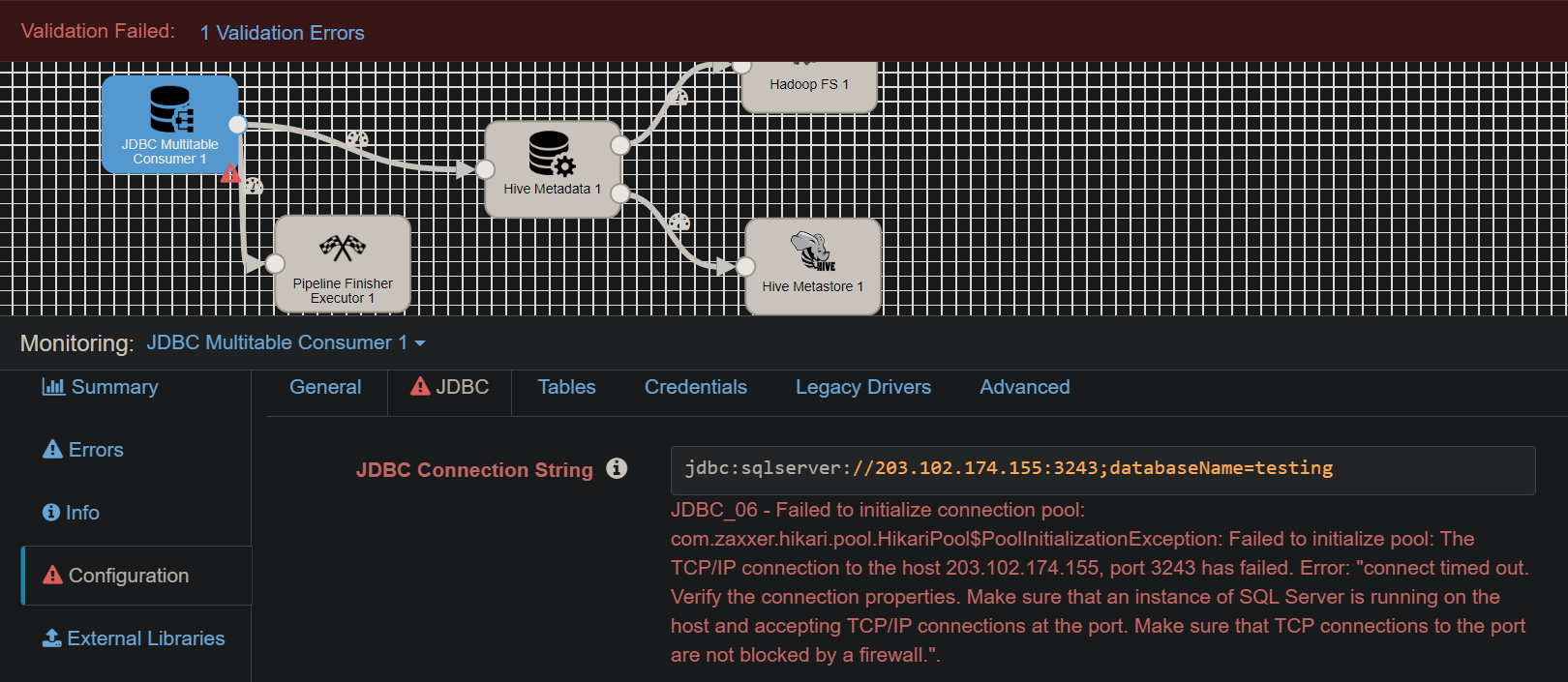
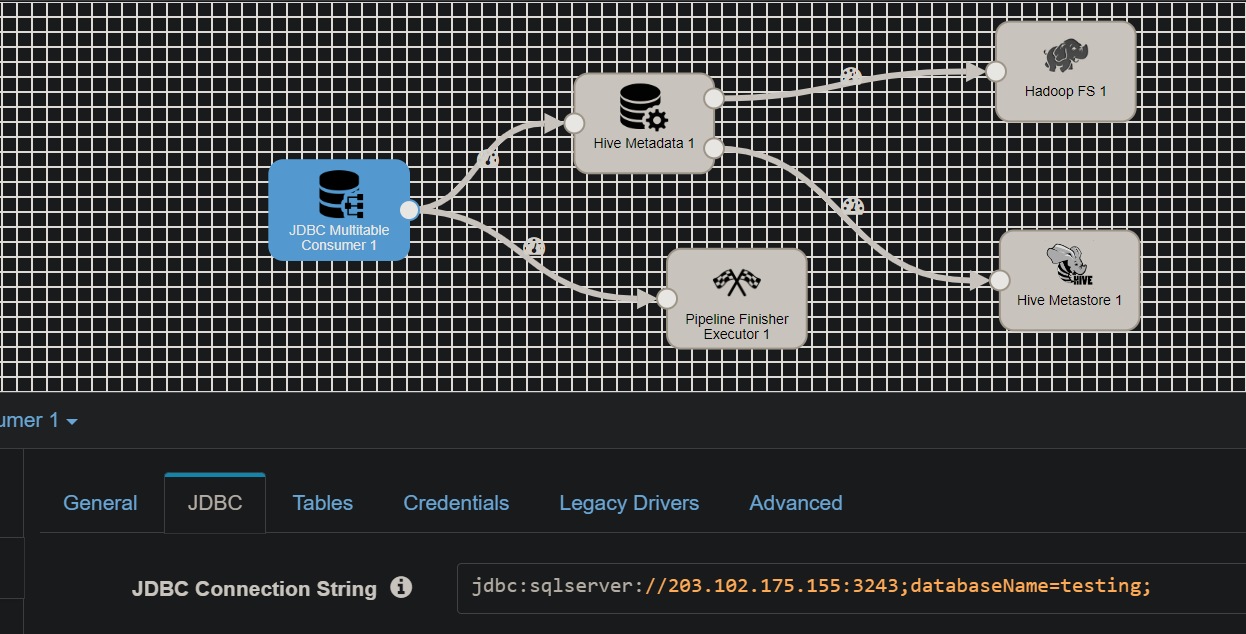
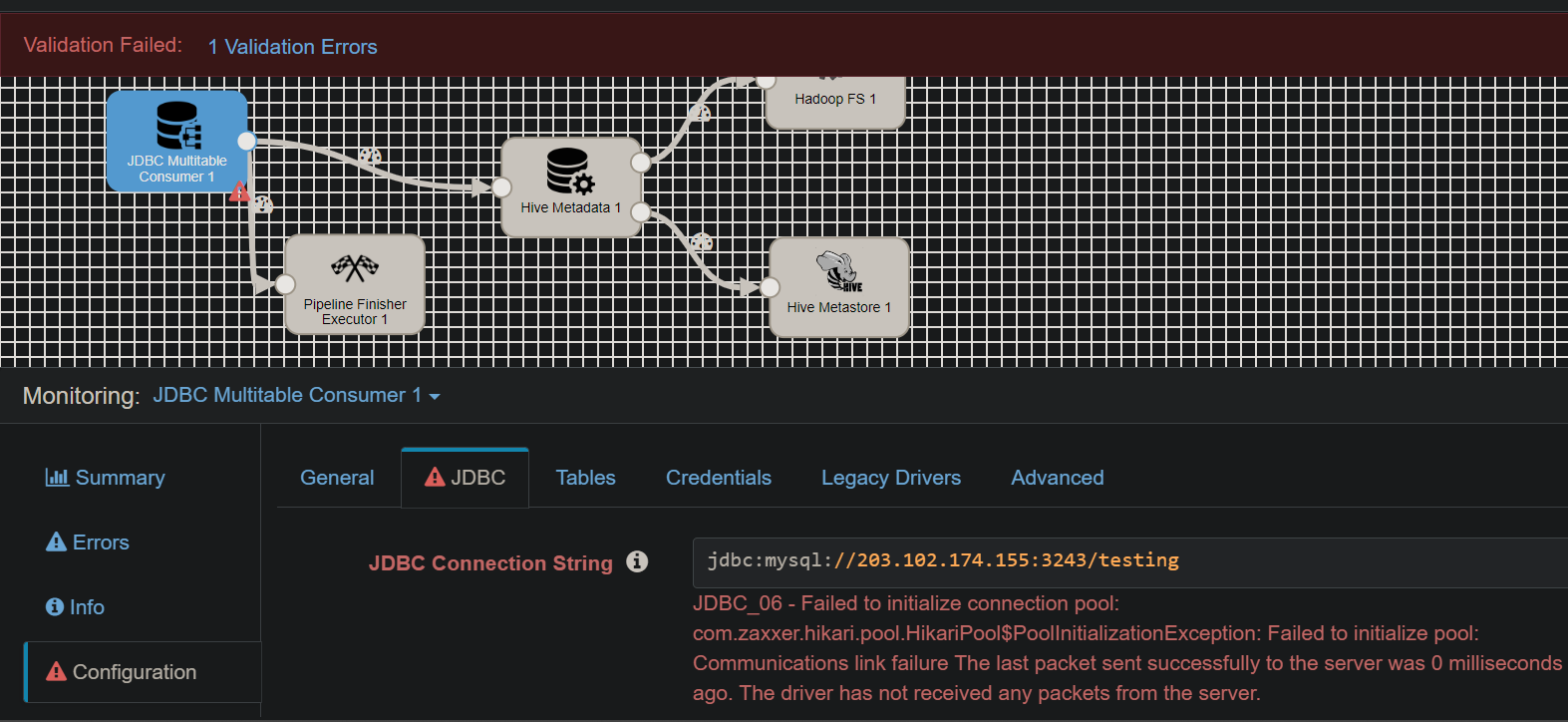
I have a task to create some backup data from sqlserver to hadoop and hive, the jdbc connection has been changed to sqlserver but it still doesn't work, please help me


Hi, I am new to Streamsets, started using it today.
I have a task to create some backup data from sqlserver to hadoop and hive, the jdbc connection has been changed to sqlserver but it still doesn't work, please help me
Best answer by Bikram
The error is saying that the ip and port is not reachable. Please check if the firewall has been opened for this to connect from streamsets.
Once the firewall opened , try to ping the ip from the command prompt to check if its reachable or not then you can try to connect it in streamsets.
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.