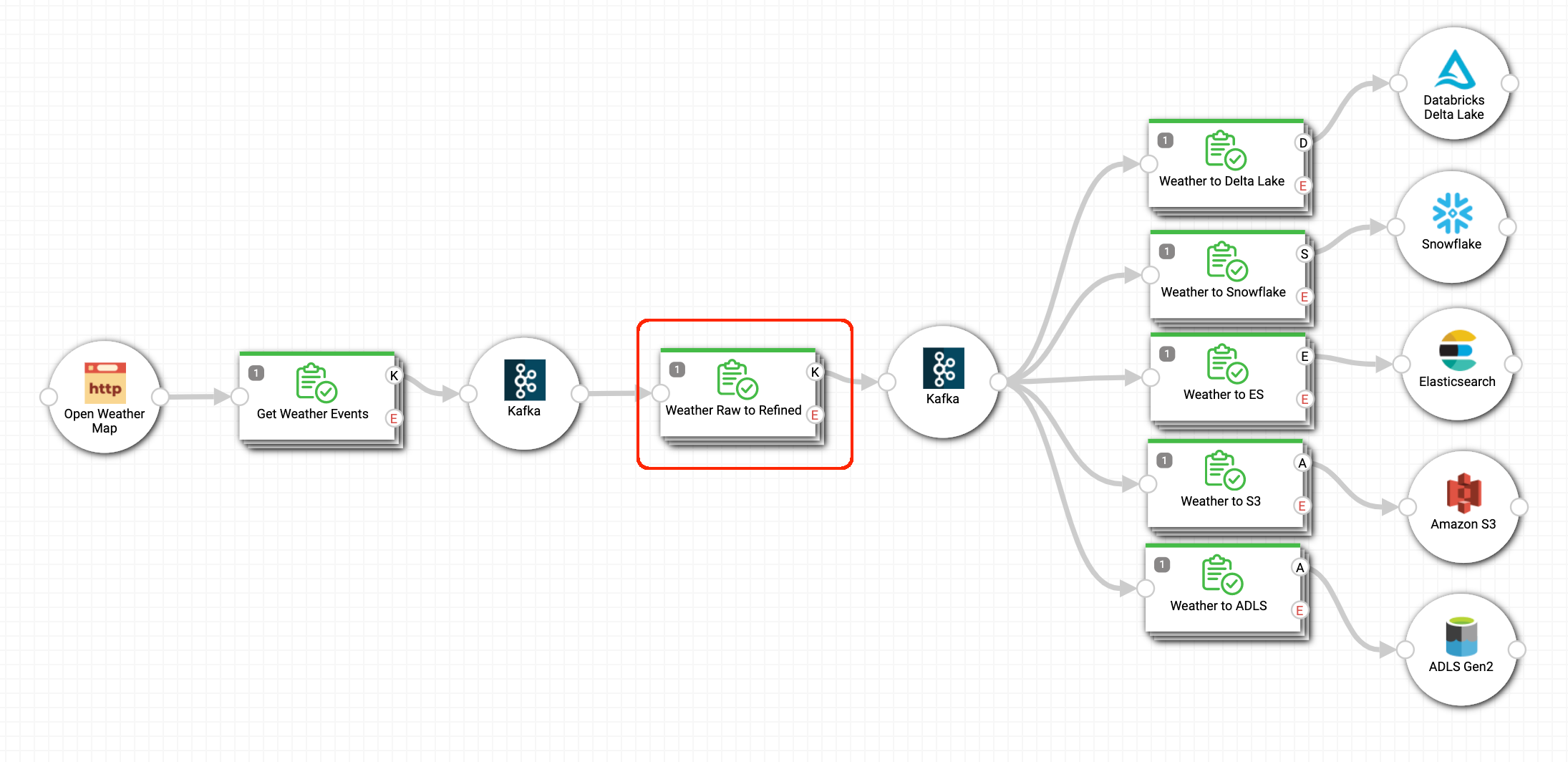
Here's a Kafka Stream Processor pipeline that reads events from a "raw" topic, performs streaming transforms, and publishes the transformed events to a "refined" topic that multiple downstream clients subscribe to:

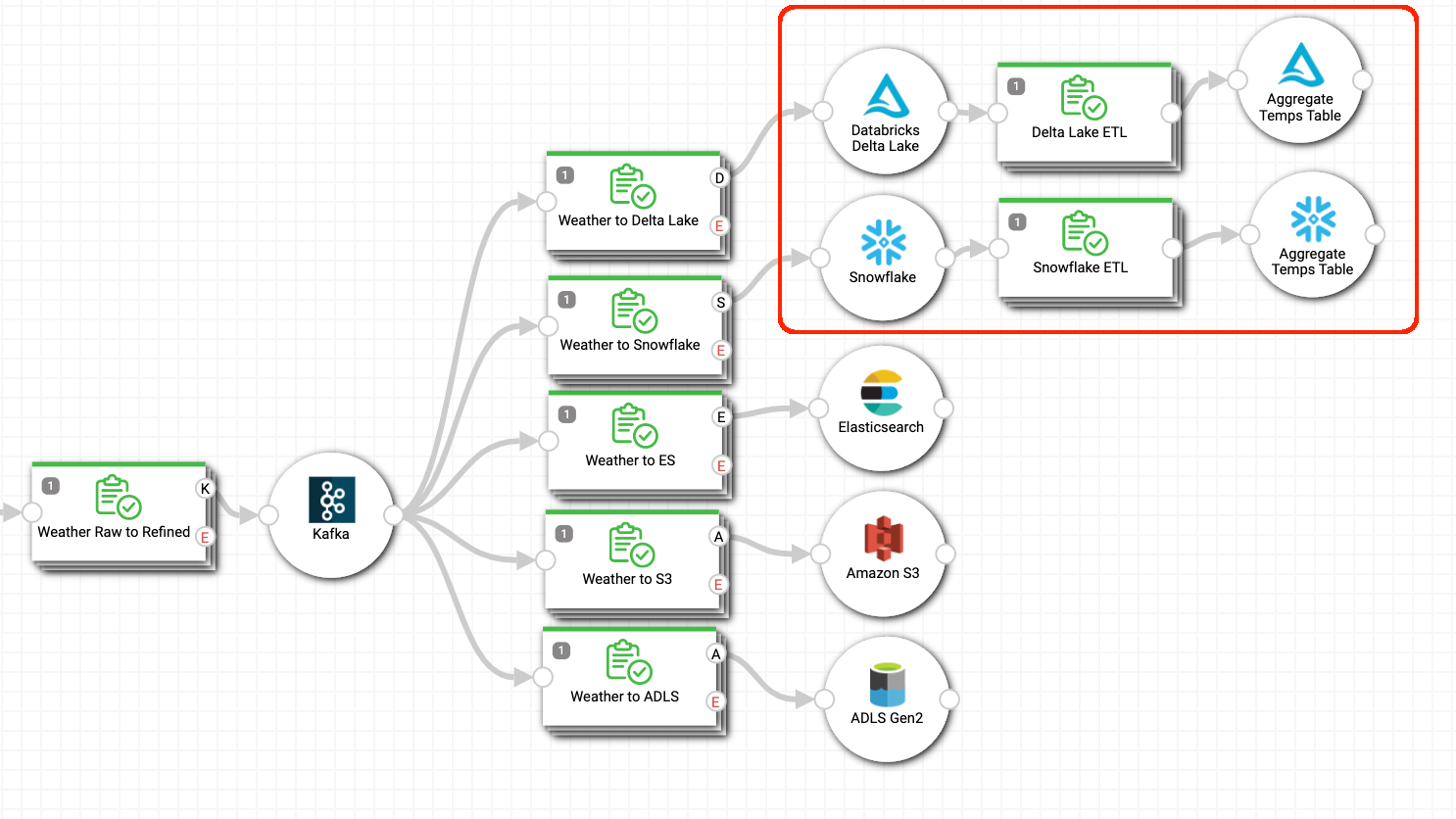
Here is the Stream Processor Pipeline’s placement within a StreamSets Topology that allows visualization and monitoring of the end-to-end data flow, with last-mile pipelines moving the refined events into Delta Lake, Snowflake, Elasticsearch, S3 and ADLS:
Users can extend the Topology using Transformer for Snowflake to perform push-down ETL on Snowflake using Snowpark, and Transformer on Databricks Spark to perform ETL on Delta Lake