I am trying to load data from Teradata to Snowflake. I am using Transformer for spark as engine.
Origin:
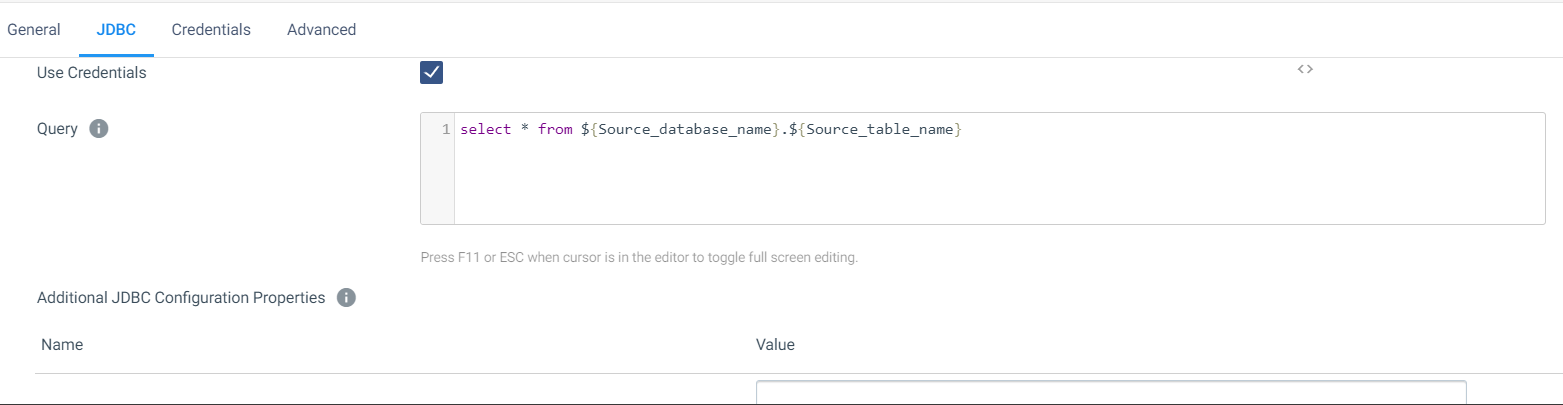
JDBC query consumer.
Destination:
Snowflake
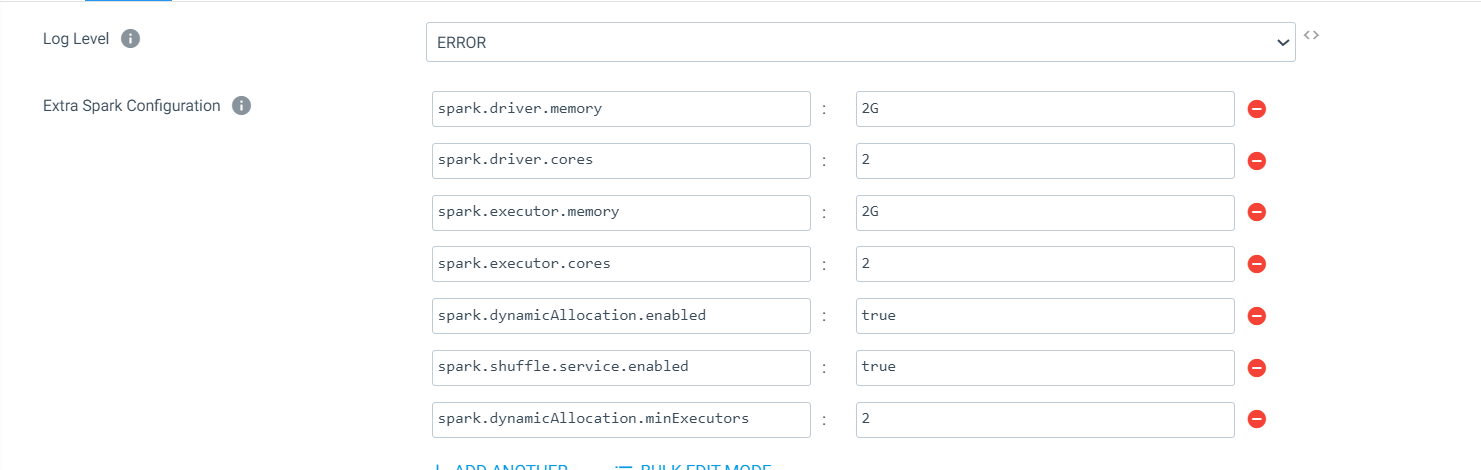
I am able to load 12 million data in 1 hour.
but I want to improve the performance.
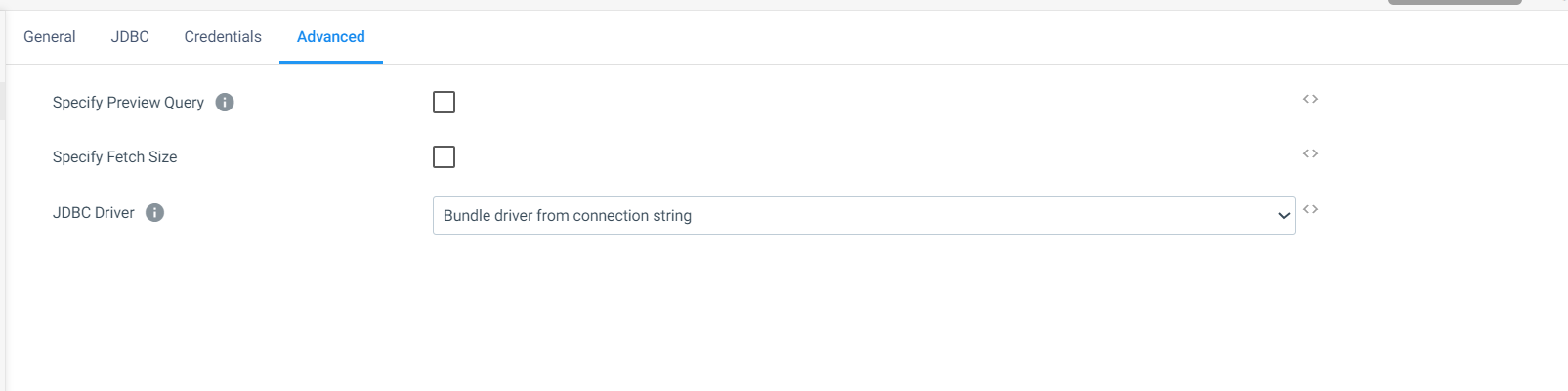
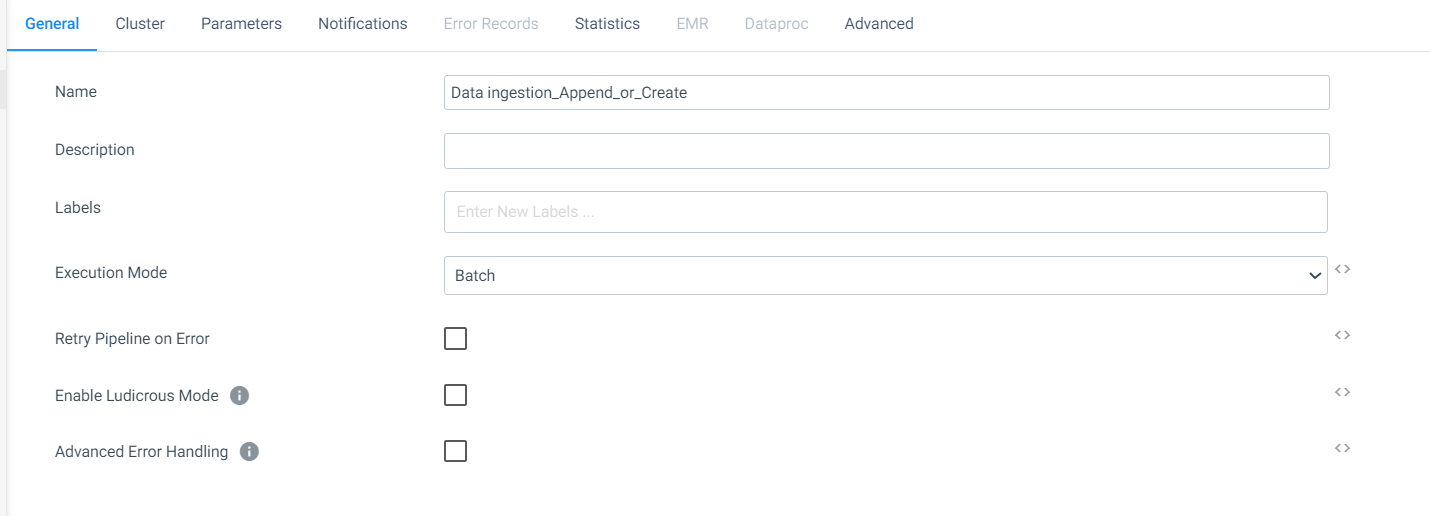
Below is the configuration of my pipeline.