
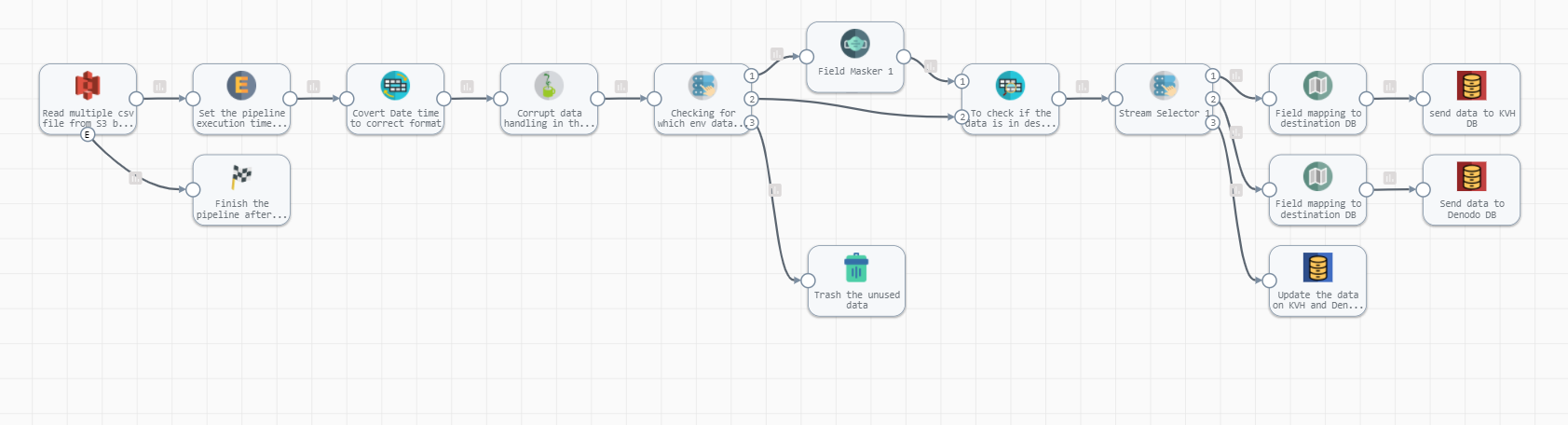
This is a generic pipeline that has been created to read multiple .csv files from AWS s3 bucket and handles corrupt data if any in the file and masks the data based on DB env and performs full and data load to the destination DB’s.
Let's deep drive into each and every processor which is being used in the pipeline.
Origin :
AWS S3 : Read multiple .csv files from the bucket.
Processors:
Expression Evaluator : This is used for setting the pipeline execution time and user to identify who executes the pipeline and when.
Field Type Converter: This is for converting time field to correct date time format (YYYY-MM-DD HH:MM:SS)
Jython Evaluator : This is for handling corrupt data if any in the file (e.g “‘ street address ’”)
Stream-sets Selector : This is for checking for which environment data needs to be masked before loading data to destination DB’s.
In this case for Dev and Test env data will be masked because of GDPR rule we couldn’t load sensitive data into it but for Prod environment no need to apply the masking.
Field Masker : This is for masking sensitive data before processing to the destination DB’s. Applicable only for Dev and Test env data loading.
If ${record:value('/sourceSys') == 'DEV' or record:value('/sourceSys') == ‘Test'} , Masking data before data load.
JDBC lookup : This is for checking if data exists in the tables based on the primary key.
If Data exists then do update data if any in DB tables else insert data to destination DB’s.
Stream selector : This is for filtering out different destination DB’s. In this case we have multiple destinations where data needs to be inserted and updated.
Field Mapper : This is for mapping source column names and its data type as per destination DB because the pipeline has JDBC as destination in it.
NB : For JDBC producer as destination please make sure that source column and its data types are matching with destination DB tables , else data won’t process in it.
Destinations :
JDBC producer 1: If data not exists in the table then pipeline will load data into TeraData DB(on premise)
JDBC producer 2 : If data does not exist in the table then pipeline will load data to Denodo DB.