



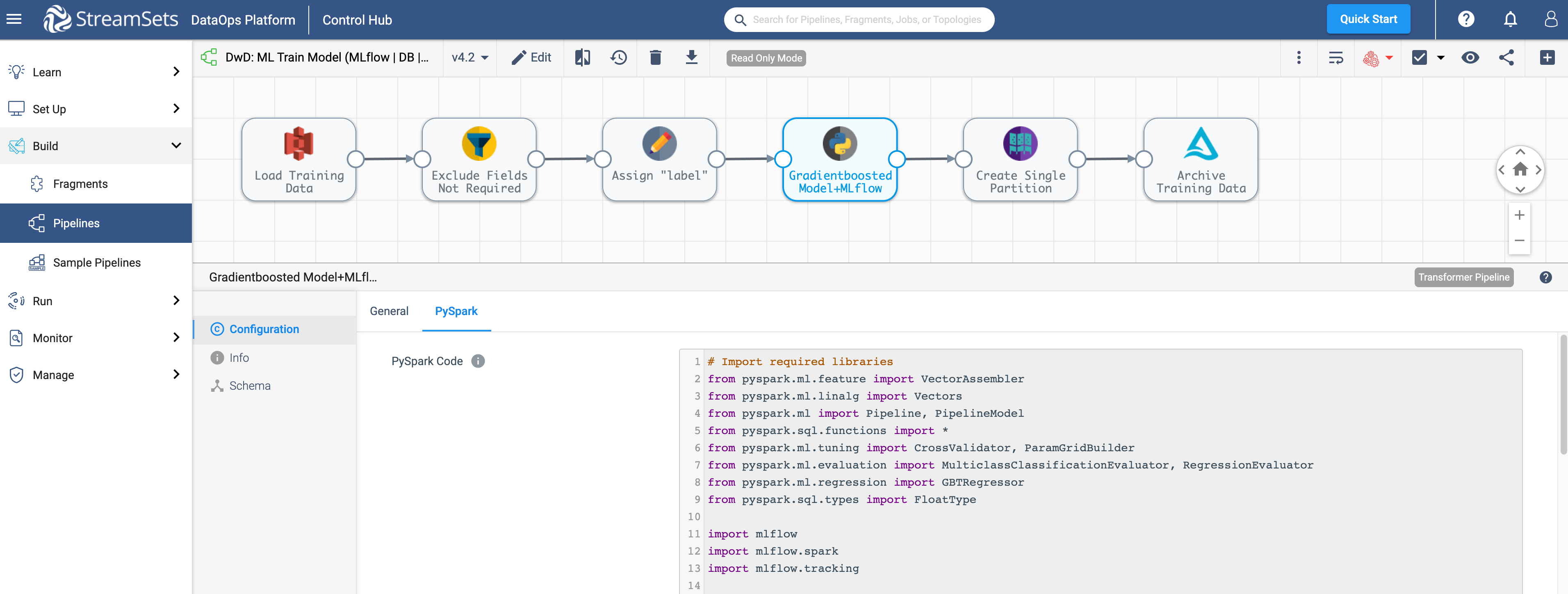
This pipeline is designed to ingest data from Amazon S3 and prepare it for training a ML model using PySpark custom processor. Once the Gradient Boosted model is trained, the model artifacts, features, accuracy of the model and other metrics are registered as an experiment in MLflow. (The pipeline runs on Databricks cluster which comes bundled with MLflow server.)