Hello,
Scenario: Multiple tables from source DB are to be replicated in the target DB. Whatever changes happen in source tables should be reflected in the target tables. When a record gets deleted, an entry with all columns of the record must be saved to a file. Both source and target are postgres DBs.
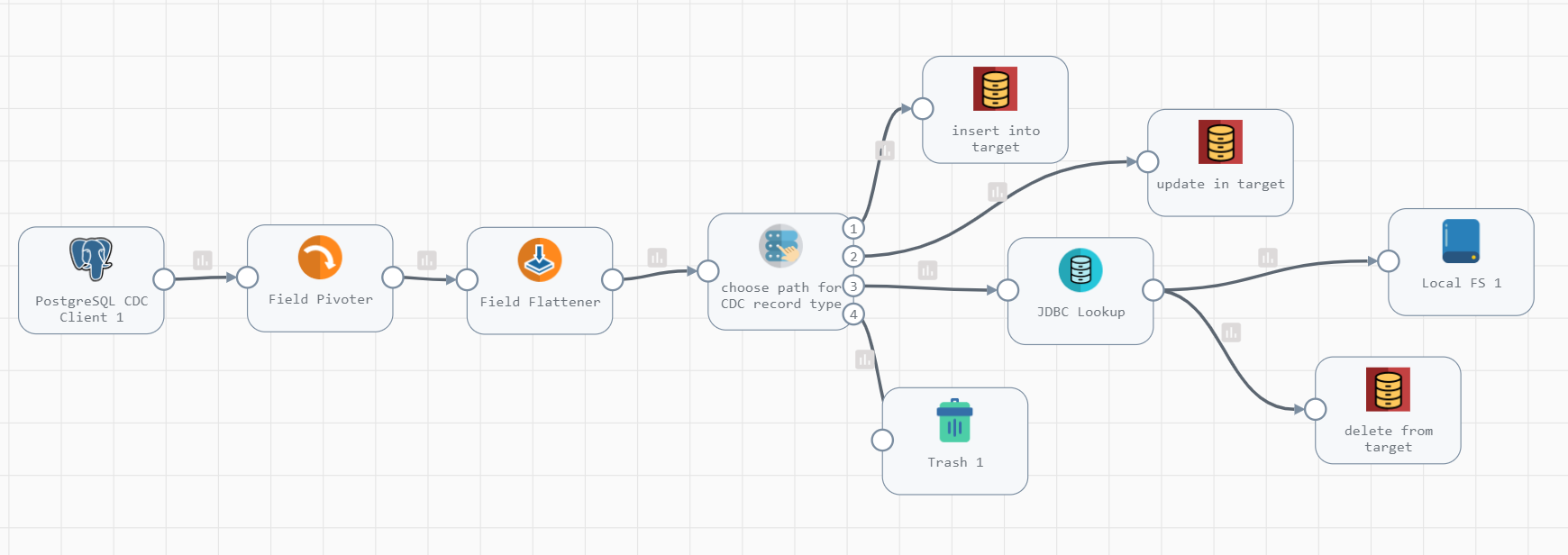
I have implemented this for a single table. Created one pipeline that simply performs one time data copy from source to target. Then created a CDC pipeline like in the picture below. I am using the JDBC Producer destination.
Though this works as designed for single table, I am not sure if this is the right approach when working with multiple tables. Though the CDC origin accepts the table name pattern “source_tab%” , the JDBC Producer destination seems to allow just one table name. i.e. though CDC is giving me all updates for all records, I can only use one table name at a time in the JDBC producer destination.
I have tried using EL in the table name e.g. ${record:attribute(/'change.table')} but got validation error.
Do I need to create multiple jobs for multiple tables and pass tables names as runtime parameters?
What is the best way to implement this? Looks like I am missing something obvious. Please help.