i trying to write avro format as wholefile format from kafka to localfs but i got error.below i share the pipeline ,can you please suggest how to done this
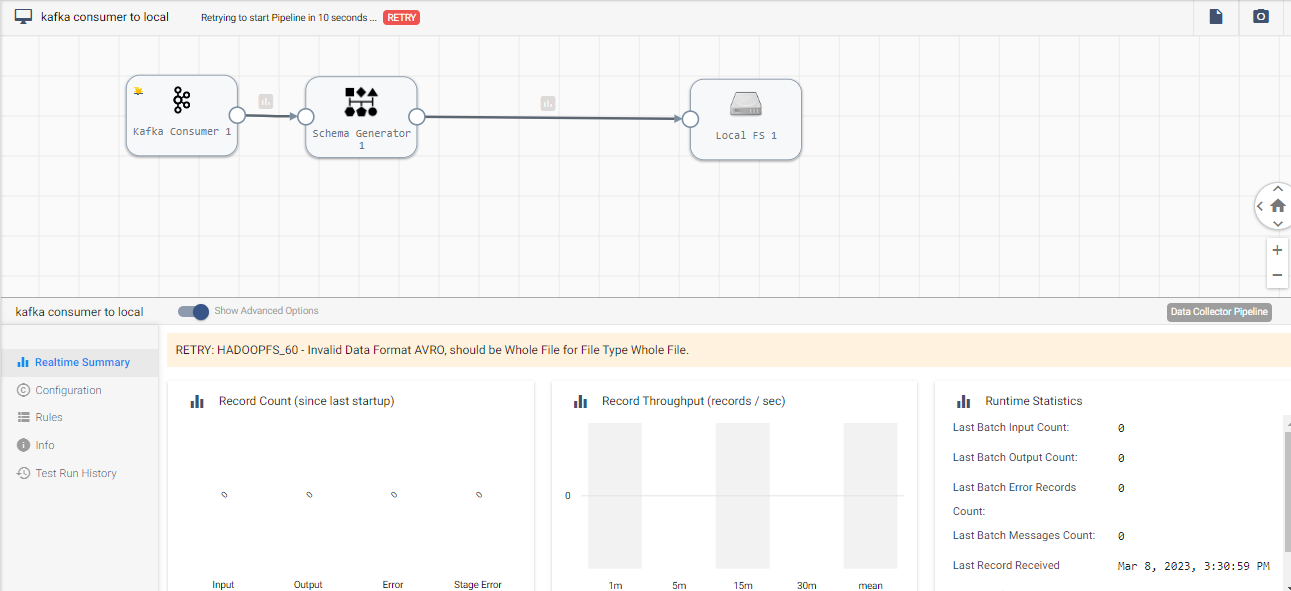

i trying to write avro format as wholefile format from kafka to localfs but i got error.below i share the pipeline ,can you please suggest how to done this
Hi
I am a bit confused. You can use the whole file data format to transfer entire files from an origin system to a destination system. With the whole file data format, you can transfer any type of file. What you are trying to do is read Kafka message in Avro so you cannot write it as a whole file.
Try writing as a .avro file in Local FS destination.
Hi
I am a bit confused. You can use the whole file data format to transfer entire files from an origin system to a destination system. With the whole file data format, you can transfer any type of file. What you are trying to do is read Kafka message in Avro so you cannot write it as a whole file.
Try writing as a .avro file in Local FS destination
But my use case is read to from kafka and then store as a parquet file .In between i used to generate as avora file and then convert into parquetfile .exact what i want is local destination support to generate text file only then how can i generate .avro file format
you can use events + executors.
Approach is very well documented here: https://docs.streamsets.com/portal/platform-datacollector/latest/datacollector/UserGuide/Solutions/Parquet.html
you can use events + executors.
Approach is very well documented here: https://docs.streamsets.com/portal/platform-datacollector/latest/datacollector/UserGuide/Solutions/Parquet.html
The sample pipeline uses hadoop FS as destination, you can use Local FS if your use cases needs to write to a directory rather than hadoop.
If you want to use hadoop then the first requirement would be to make sure that your SDC has access to your hadoop file system. The other properties are pretty straight forward as shown here https://docs.streamsets.com/portal/platform-datacollector/latest/datacollector/UserGuide/Destinations/HadoopFS-destination.html#concept_awl_4km_zq
The sample pipeline uses hadoop FS as destination, you can use Local FS if your use cases needs to write to a directory rather than hadoop.
If you want to use hadoop then the first requirement would be to make sure that your SDC has access to your hadoop file system. The other properties are pretty straight forward as shown here https://docs.streamsets.com/portal/platform-datacollector/latest/datacollector/UserGuide/Destinations/HadoopFS-destination.html#concept_awl_4km_zq
The sample pipeline uses hadoop FS as destination, you can use Local FS if your use cases needs to write to a directory rather than hadoop.
If you want to use hadoop then the first requirement would be to make sure that your SDC has access to your hadoop file system. The other properties are pretty straight forward as shown here https://docs.streamsets.com/portal/platform-datacollector/latest/datacollector/UserGuide/Destinations/HadoopFS-destination.html#concept_awl_4km_zq
my use_case if it possibile to sql server origin to kafka write it in avro format and then kafka consumer to in local fs as whole file format and then transfer it to avro to parquet in whole file format by another pipeline.if it possibile...
I usually do it in this way : Create a Kafka consumer instance to consume messages from a Kafka topic. Then set the consumer's properties including the Kafka bootstrap servers, group ID, and other relevant configuration properties. Then use the consumer's poll() method to retrieve messages from the Kafka topic. For each message retrieved, extract the Avro payload from the Kafka message. Write the Avro payload to a file on the local filesystem using the WholeFile format. And commit the offset of the last message processed to Kafka to ensure that the consumer does not process the same message again.
view software project
I usually do it in this way : Create a Kafka consumer instance to consume messages from a Kafka topic. Then set the consumer's properties including the Kafka bootstrap servers, group ID, and other relevant configuration properties. Then use the consumer's poll() method to retrieve messages from the Kafka topic. For each message retrieved, extract the Avro payload from the Kafka message. Write the Avro payload to a file on the local filesystem using the WholeFile format. And commit the offset of the last message processed to Kafka to ensure that the consumer does not process the same message again.
view software project
below I share my screeenshot for the kafka configuration and pipeline
The first couple of paragraphs for Whole File Transformer processor document says this:
The Whole File Transformer processor transforms fully written Avro files to highly efficient, columnar Parquet files. Use the Whole File Transformer in a pipeline that reads Avro files as whole files and writes the transformed Parquet files as whole files.
Origins and destinations that support whole files include cloud storage stages such as Amazon S3, Azure Data Lake Storage, and Google Cloud Storage, and as well as local and remote file systems such as Local FS, SFTP/FTP/FTPS Client, and Hadoop FS. For a full list of whole file origins and destinations or more information about the whole file data format.
Kafka does not support whole files. You will have to write the kafka messages to a file and then create an event that fires when the file finishes. There you can use this transformer to convert your Avro file to Parquet.
Also, StreamSets automatically reads the next message and also the offset management is handled by Kafka so you dont have to worry about it.
The first couple of paragraphs for Whole File Transformer processor document says this:
The Whole File Transformer processor transforms fully written Avro files to highly efficient, columnar Parquet files. Use the Whole File Transformer in a pipeline that reads Avro files as whole files and writes the transformed Parquet files as whole files.
Origins and destinations that support whole files include cloud storage stages such as Amazon S3, Azure Data Lake Storage, and Google Cloud Storage, and as well as local and remote file systems such as Local FS, SFTP/FTP/FTPS Client, and Hadoop FS. For a full list of whole file origins and destinations or more information about the whole file data format.
Kafka does not support whole files. You will have to write the kafka messages to a file and then create an event that fires when the file finishes. There you can use this transformer to convert your Avro file to Parquet.
can you please provide some pipeline to achieve the these usecase.
my use_case is sqlserver origin to kafka write it in avro format and then kafka consumer to in local fs as whole file format and then transfer it to avro to parquet in whole file format by another pipeline or with in the same 2pipeline .
Hi Praveen P
Did you get the proper solution for your query. I also have some similar kind of requirement.
Can you share the solution with us.
Thanks in advance.
Hi Praveen P
Did you get the proper solution for your query. I also have some similar kind of requirement.
Can you share the solution with us.
Thanks in advance.
Hi Shirin
No, Till now i not get the answer
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.