



Question:
We are trying to do a Hive/Impala Data Drift in cluster streaming mode. However, the pipeline stalls (new partitions) and often fails (new columns) when jobs try to simultaneously hit the Hive/Impala Executor.
Should we be streaming all the Data Drift events to a single pipeline and de-dupe them to manage the Hive/Impala changes?
What is the recommended way to proceed here?
Answer:
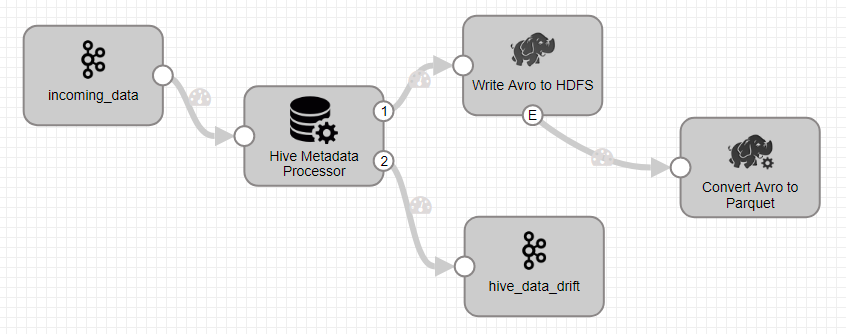
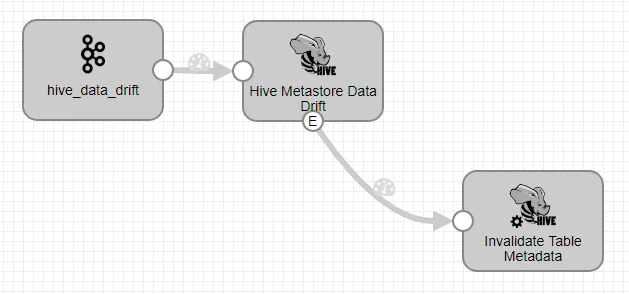
The general recommendation is not to hit the Hive Metastore from multiple pipelines. The reason behind this approach revolves around the premise that two pipelines could try to create a table or add a column at the same time. Having Hive Metastore target, hence, in a separate pipeline and funneling all the metadata records via Kafka/SDC RPC is the optimal way to design it in such a scenario.
The Hive metastore target is capable of de-duplicating events and manages that with just one query if it is all done via a single instance of the stage. And, this is applicable for cluster pipelines/multiple standalone pipelines. For multi-threaded pipelines, it is not needed because we make use of the shared cache.
Note: If using Kafka stage to process the records from the pipeline to another pipeline with Hive Metastore destination, make sure that you pick SDC Record Data type.