



If you have input data which has multi-character delimiters and need to split it for subsequent processing you may want to look at the capabilities of Field Splitter.
You can, for example, couple the Directory Origin with a Field Splitter Processor. In Directory Origin, set the Data Format tab to "Text". This will place each record (up to line terminator) into the /text field.
Set the Field Splitter Processor as the next stage in the pipeline and configure it as follows:
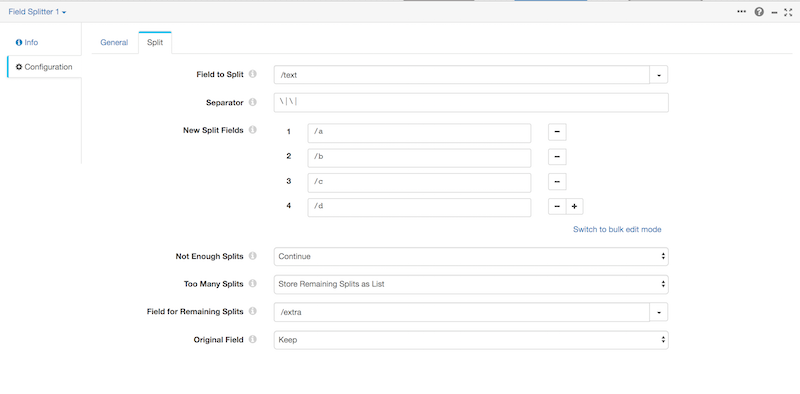
An important point to note is the Separator - regexes are permitted in this field. If you want to specify the Separator literally, not as a regex, you must be careful escape the characters which could be interpreted as part of a regex. In our example, the fields are separated by two "literal" pipe characters, which must be escaped.
The Field Splitter solution does not provide for gathering the names in the header record as field names, so you should also set up a mapping in the "New Split Fields" section of the UI.
Given this input data:
three||little||||kittens||lost their mittens
they||||didn't||get||any pie
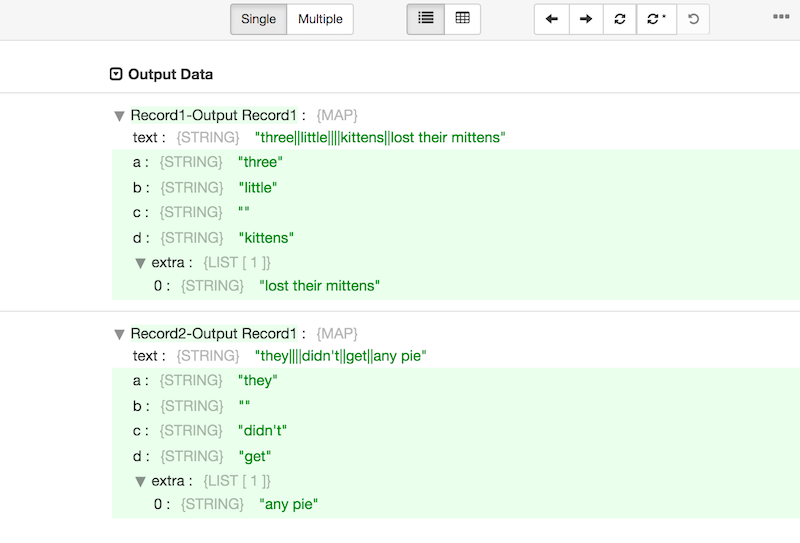
Fields that are empty in the data are still parsed and a placeholder "" is inserted into the corresponding "New Split Field". This keeps each field in the correct column.
Also, note that the only characters which are interpreted is the delimiter. In this example, the apostrophe in "didn't" was not interpreted - some parsers may have interpreted this as an unmatched quote, and would then fail to parse this line of text.